
📖 톰캣
자바 17 버전 또는 그 이상으로 사용.
톰캣 10버전 이상으로 다운
📌 톰캣 실행 (윈도우)
설치한 톰캣폴더/bin 폴더로 이동
실행 : startup.bat
종료 : shutdown.bat
URL localhost:8080으로 접근하면 톰캣 서버가 실행됐는지 확인할 수 있다.
톰캣 실행했는데 접근이 되지 않으면 실행 로그를 확인한다. 실행 로그는 톰캣폴더/logs/catalina.out을 확인
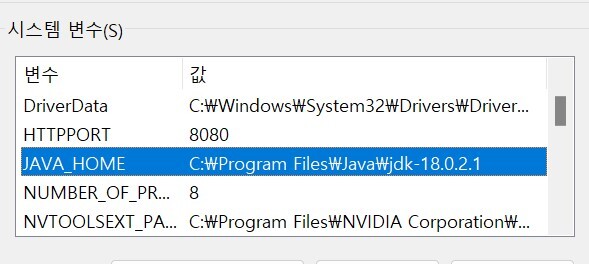
✯ "사이트에 연결할 수 없음.
localhost에서 연결을 거부했습니다." 의 에러가 발생한 경우 꼭 자바 18버전이 맞는지 확인하고 환경 변수 JAVA_HOME의 경로를 제대로 입력했는지 확인.
📖 WAR 빌드와 배포
- 윈도우는 gradlew build를 해서 war 생성
(cmd에서 반드시 프로젝트가 있는 곳으로 폴더 이동해서 gradlew build를 입력.) - WAR 파일 생성 확인
-> build/libs/server-0.0.1-SNAPSHOT.war - 압축 풀기
jar -xvf server-0.0.1-SNAPSHOT.war
여기까지 하면 build 폴더에 여러 폴더들과 파일들이 생성됨.
📌 JAR와 WAR
JAR는 자바에서 여러 클래스와 리소스를 묶어서 JAR라고 하는 압축 파일을 만들 수 있는데 이 파일은 JVM 위에서 직접 실행되거나 또는 다른 곳에서 사용하는 라이브러리로 제공된다.
직접 실행하는 경우 main() 메서드가 필요함.
WAR는 웹 애플리케이션 서버(WAS)에 배포할 때 사용하는 파일이다. 웹 애플리케이션 서버 위에서 실행되고 HTML 같은 정적 리소스와 클래스 파일을 모두 함께 포함하기 때문에 구조가 JAR보다 복잡하다.
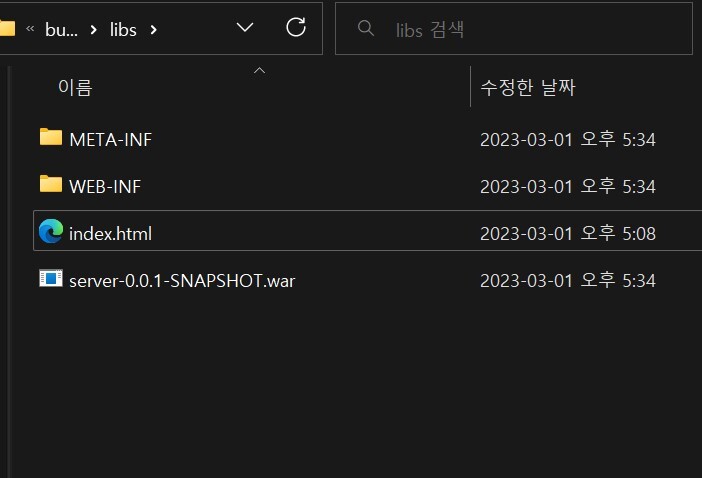
WAR 구조 (꼭 지키기)
✳ WEB-INF
➴classes : 실행 클래스 모음
➴lib : 라이브러리 모음
➴web.xml : 웹 서버 배치 설정 파일(생략 가능)
✳ index.html
WEB-INF를 제외한 나머지 영역은 HTML, CSS 같은 정적 리소스가 사용되는 영역이다.
📌 WAR 배포
- WAR를 배포하려면 반드시 톰캣 서버를 종료해야 한다.
- 톰캣 폴더에서 webapps에 있는 모든 폴더 들을 삭제.
- build/libs/server-0.0.1-SNAPSHOT.war 이 파일을 복사해서 webapps에 넣어줌. (꼭 대문자로 이름 수정)
- 다시 톰캣 실행
📖 인텔리제이 톰캣 설정 (유료 버전)
- 인텔리제이의 메뉴에 Run -> run... 으로 가서 Run configuration.
-
- 선택해서 맞는 버전으로 톰캣 서버 설정
- Deployment로 가서 + 선택 -> artifact 클릭하고 war 파일 선택.
- Deployment 밑에 보면 Application context에 war 파일 입력되어 있는데 삭제해줌.
- apply 하고 run.
만약 8080이 이미 사용 중이라고 하면 꺼주기.
📖 서블릿 컨테이너 초기화
ServletContainerInitializer라는 초기화 인터페이스 사용.
서블릿 컨테이너를 초기화하는 기능을 제공.
ServletContext ctx : 서블릿 컨테이너 자체의 기능을 제공, 이 객체를 통해 필터나 서블릿을 등록할 수 있다.
톰캣을 실행할 때 호출이 되는지 확인.
public class MyContainerInitV1 implements ServletContainerInitializer {
@Override
public void onStartup(Set<Class<?>> c, ServletContext ctx) throws ServletException {
System.out.println("MyContainerInitV1.onStartup");
System.out.println("MyContainerInitV1 c = " + c);
System.out.println("MyContainerInitV1 ctx = " + ctx);
}
}인터페이스 구현하고나서 서블릿 컨테이너에게 초기화 메서드가 무엇인지 알려줘야 한다.
1. resources -> META-INF -> services -> jakarta.servlet.ServletContainerInitializer
- Initializer 파일 안에 패키지 포함해서 hello.container.MyContainerInitV1 입력.
톰캣을 실행하면 hello.container.MyContainerInitV1를 보고 서블릿 컨테이너 초기화 시점에 onStartup 메서드를 호출해준다.
결과
MyContainerInitV1.onStartup
MyContainerInitV1 c = null
MyContainerInitV1 ctx = org.apache.catalina.core.ApplicationContextFacade@256acd95
WAS를 실행하면 onStartup이 먼저 실행된 것을 확인할 수 있다.
📖 서블릿 컨테이너 초기화 (좀 더 자세히)
서블릿을 서블릿 컨테이너 초기화 시점에 프로그래밍 방식으로 직접 등록.
HelloServlet을 서블릿 컨테이너에 직접 등록했다.
📌 서블릿 등록 2가지가 있는데 프로그래밍 방식을 사용하는 이유
@WebServlet을 사용하면 서블릿 등록하기에 편하지만 애노테이션을 사용하면 유연하게 변경하는 것이 어렵다. (하드코딩 된 것처럼.)
직접 등록은 무한한 유연성을 제공한다. /test 처럼 이 경로를 유연하게 변경할 수 있다.
public interface AppInit {
void onStartup(ServletContext servletContext);
}public class AppInitV1Servlet implements AppInit {
@Override
public void onStartup(ServletContext servletContext) {
System.out.println("AppInitV1Servlet.onStartup");
//순수 서블릿 코드 등록 -> 서블릿을 프로그램 방식으로 등록하는 것
ServletRegistration.Dynamic helloServlet =
servletContext.addServlet("helloServlet", new HelloServlet());
helloServlet.addMapping("/hello-servlet");
}
}📖 애플리케이션 초기화
위에서 서블릿 초기화라는 것을 했고 이번에는 애플리케이션 초기화라는 것이다. (2개가 다름.)
서블릿 컨테이너 초기화가 먼저 일어나고 코드를 엮어서 애플리케이션 초기화를 호출해주는 것이다.
애플리케이션 초기화하려면 인터페이스가 반드시 필요.
@HandlesTypes(AppInit) : AppInit을 구현한 구현체들 AppInitV1Servlet를 잡아와서 클래스 정보를 넘겨준다.
@HandlesTypes(AppInit.class)
public class MyContainerInitV2 implements ServletContainerInitializer {
@Override
public void onStartup(Set<Class<?>> c, ServletContext ctx) throws ServletException {
System.out.println("MyContainerInitV2.onStartup");
System.out.println("c = " + c);
System.out.println("ctx = " + ctx);
for (Class<?> appInitClass : c) {
try {
//new AppInitV1Servlet()과 같은 코드이다.
AppInit appInit = (AppInit) appInitClass.getDeclaredConstructor().newInstance();
appInit.onStartup(ctx); //직접 호출
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
}애플리케이션 초기화
1. @HandlesTypes() 애노테이션에 애플리케이션 초기화 인터페이스를 지정.
2.서블릿 컨테이너 초기화는 파라미터로 넘어오는 Set<Class<?>> c 에 애플리케이션 초기화 인터페이스의 구현체들을 모두 찾아서 클래스 정보로 전달.
3.appInitClass.getDeclaredConstructor().newInstance();로 리플렉션을 사용해서 객체를 생성.
4.appInit.onStartup(ctx)로 애플리케이션 초기화 코드를 직접 실행하며넛 서블릿 컨테이너 정보가 담긴 ctx도 함께 전달.
✩ 실행하려면 서블릿 컨테이너에게 알려줘야 하기 때문에 jakarta.servlet.ServletContainerInitializer에 설정 추가 잊지 말것.
📌 애플리케이션 초기화를 하는 이유
➙ 서블릿 컨테이너를 초기화하려면 인터페이스를 구현한 코드를 만들고 jakarta.servlet.Servlet~~~ 파일에 해당 코드를 직접 지정해주어야 하는데 애플리케이션 초기화는 특정 인터페이스만 구현하면 된다.
➙ 그리고 아무 의존 관계없이 원하는 모양으로 인터페이스를 만들 수 있다.
📖 스프링 컨테이너 등록
- 스프링 컨테이너 생성.
- 스프링 MVC 컨트롤러를 스프링 컨테이너에 빈으로 등록.
- 스프링 MVC를 사용하는데 필요한 디스패쳐 서블릿을 서블릿 컨테이너에 등록.
@Configuration
public class HelloConfig {
@Bean //수동 등록.
public HelloController helloController() {
return new HelloController();
}
}@RestController
public class HelloController {
@GetMapping("/hello-spring")
public String hello() {
System.out.println("HelloController.hello");
return "hello spring!!";
}
}public class AppInitV2Spring implements AppInit {
@Override
public void onStartup(ServletContext servletContext) {
System.out.println("AppInitV2Spring.onStartup");
//바로 호출이 된다.
//인터페이스만 구현하면 자동으로 모두 실행이 된다.
//c = [class hello.container.AppInitV2Spring, class hello.container.AppInitV1Servlet]
//현재 2개 모두 AppInit 인터페이스를 구현해서 모두 실행이 되는 것이다.
//스프링 컨테이너 생성
AnnotationConfigWebApplicationContext appContext = new AnnotationConfigWebApplicationContext();
//생성 후 설정으로 HelloConfig를 가져다 쓰면 HelloController가 등록이 된다.
appContext.register(HelloConfig.class);
//스프링 MVC 디스패쳐 서블릿 생성, 스프링 컨테이너 연결
DispatcherServlet dispatcher = new DispatcherServlet(appContext);
//디스패쳐 서블릿을 서블릿 컨테이너에 등록.
ServletRegistration.Dynamic servlet = servletContext.addServlet("dispatcherV2", dispatcher);
// /spring/* 요청이 디스패쳐 서블릿을 통하도록 설정.
// 저 경로라면 디스패쳐 서블릿으로 다 들어감.
servlet.addMapping("/spring/*");
}
}서블릿을 등록할 때 이름은 원하는 것으로 해도 되지만 같은 이름으로 중복 등록하면 에러가 발생하므로 주의.
localhost~~/spring/spring-hello를 실행했는데 처음에 dispatcherV2라는 디스패쳐 서블릿이 실행되면 /spring가 실행되고 dispatcherV2 디스패쳐 서블릿은 스프링 컨트롤러를 찾아서 실행되면 /hello-spring이 실행된다.
마지막으로 서블릿을 찾아서 호출하는데 사용된 /spring을 제외한 /hello-spring이 매핑된 컨트롤러 HelloController의 메서드를 찾아서 실행한다.
즉 /spring/의 하위 폴더인 로 스프링 컨트롤러를 찾는다.
📖 스프링 MVC 서블릿 컨테이너 초기화 지원
초기화하기 위해 ServletContainerInitializer 인터페이스 구현하고 코기화 코드 만들고 애플리케이션 초기화를 위해 @HandlesTypes 애토페이션 적용시키고 jakarta.servlet~~~ 파일에 서블릿 컨테이너 초기화 클래스 경로를 등록하는 과정 매우 번거롭다.
이제는 편하게 서블릿 컨테이너 초기화 과정 생략하고 애플리케이션 초기화 코드만 작성하면 된다.
WebApplicationInitializer 인터페이스 가져오면 끝.
public class AppInitV3SpringMvc implements WebApplicationInitializer {
@Override
public void onStartup(ServletContext servletContext) throws ServletException {
System.out.println("AppInitV3SpringMvc.onStartup");
//스프링 컨테이너 생성
AnnotationConfigWebApplicationContext appContext = new AnnotationConfigWebApplicationContext();
//생성 후 설정으로 HelloConfig를 가져다 쓰면 HelloController가 등록이 된다.
appContext.register(HelloConfig.class);
//스프링 MVC 디스패쳐 서블릿 생성, 스프링 컨테이너 연결
DispatcherServlet dispatcher = new DispatcherServlet(appContext);
//디스패쳐 서블릿을 서블릿 컨테이너에 등록.
ServletRegistration.Dynamic servlet = servletContext.addServlet("dispatcherV3", dispatcher);
// 모든 요청이 디스패쳐 서블릿을 통하도록 설정.
servlet.addMapping("/");
}
}spring-web 라이브러리에 서블릿 컨테이너 초기화를 위한 등록 파일이 있고 이곳에 서블릿 컨테이너 초기화 클래스가 등록되어 있어 WebApplicationInitializer 인터페이스 하나로 애플리케이션 초기화가 가능한 것이다.
📖 WAR 배포 방식의 단점
웹 애플리케이션 개발하고 배포하는 과정
1. 톰캣 같은 WAS를 별도로 설치.
2. 애플리케이션 코드를 WAR로 빌드
3. 빌드한 WAR 파일을 WAS에 배포
이 과정의 단점
✘ WAS 별도 설치
✘ 개발 환경 설정이 복잡.
↬ 자바라면 별도의 설정 없이 main() 메서드만 실행했음.
↬ WAS 실행하고 WAR와 연동하기위한 복잡한 설정이 들어감.
✘ 배포 과정이 복잡하고 톰캣 버전 변경하려면 톰캣을 다시 설치.
그래서 설치형이 아닌 내장형으로 톰캣을 사용함.
📖 내장 톰캣
build.gradle에 추가.
implementation 'org.apache.tomcat.embed:tomcat-embed-core:10.1.5'
public class EmbedTomcatServletMain {
public static void main(String[] args) {
System.out.println("EmbedTomcatServletMain.main");
//서블릿 등록
Context context = tomcat.addContext("", "/");
tomcat.addServlet("", "helloServlet", new HelloServlet());
//helloServlet이 실행되도록 연결해준다는 의미.
context.addServletMappingDecoded("/hello-serlvet", "helloServlet");
tomcat.start();
}
}📖 내장 톰캣 스프링
public static void main(String[] args) throws LifecycleException {
System.out.println("EmbedTomcatSpringMain.main");
//톰캣 설정
Tomcat tomcat = new Tomcat();
Connector connector = new Connector();
connector.setPort(8080);
tomcat.setConnector(connector);
//스프링 컨테이너 생성
AnnotationConfigWebApplicationContext appContext = new AnnotationConfigWebApplicationContext();
appContext.register(HelloConfig.class);
//스프링 MVC 디스패쳐 서블릿 생성, 스프링 컨테이너 연결
DispatcherServlet dispatcher = new DispatcherServlet(appContext);
//서블릿 컨테이너에 디스패쳐 서블릿 등록
Context context = tomcat.addContext("", "/");
tomcat.addServlet("", "dispatcher", dispatcher);
context.addServletMappingDecoded("/", "dispatcher");
tomcat.start();
}📖 내장 톰캣 빌드, 배포
자바의 메인 메서드를 실행하기 위해서는 jar 형식으로 빌드를 해야 한다.
jar 안에는 META-INF/MANIFEST.MF 파일에 실행할 main() 메서드의 클래스를 지정해주어야 한다.
gradle
//일반 Jar 생성
task buildJar(type: Jar) {
manifest {
attributes 'Main-Class': 'hello.embed.EmbedTomcatSpringMain'
}
with jar
}빌드 jar 실행
1. cmd에서 gradlew clean buildJar
2. java -jar embed-0.0.1-SNAPSHOT.jar (에러 발생!!)
오류: 기본 클래스 hello.embed.EmbedTomcatSpringMain을(를) 초기화할 수 없습니다.
원인: java.lang.NoClassDefFoundError: org/springframework/web/context/WebApplicationContext
📌 에러 발생 이유
압축을 풀어보니 (jar -xvf embed-0.0.1-SNAPSHOT.jar) 라이브러리가 존재하지 않는다. 그리고 스프링 프레임워크 jar도 없고 톰캣 jar도 없다. 그냥 만들었던 소스 코드만 들어있다. 그래서 에러가 발생한 것이다.
WAR를 압축 풀기 했을 때는 내부에 라이브러리 역할을 하는 jar 파일을 가지고 있었다. 하지만 jar파일은 jar파일을 포함할 수 없다.
📖 내장 톰캣 빌드, 배포 (jar 해결 방법.)
대안으로 fat jar 또는 uber jar 방법을 사용한다.
Jar 안에는 Jar를 포함할 수 없지만 클래스는 얼마든지 포함할 수 있다. 라이브러리에 사용되는 jar를 풀면 class들이 튀어나온다.
cmd에서 gradlew clean buildFatJar 실행
embed-0.0.1-SNAPSHOT.jar가 존재하게 되는데 용량이 10메가로 좀 크다.
jar 압풀 풀기 : jar -xvf embed-0.0.1_SNAPSHOT.jar
Jar를 풀어보면 만든 클래스를 포함해서 많은 라이브러리들에서 제공되는 클래스들이 포함돼있는 것을 확인할 수 있다.
Fat Jar 장점
1. Fat Jar 덕분에 하나의 jar 파일에 필요한 라이브러리들을 내장할 수 있게 됨.
2. 내장 톰캣 라이브러리를 jar 내부에 내장할 수 있게 됨.
3. 하나의 jar 파일로 배포부터 웹 서버 설치 + 실행까지 모든 것을 단순화 할 수 있게 됨.
그래도 단점 존재
1. 어떤 라이브러리가 포함되어 있는지 확인하기가 어렵다. (모두 class로 풀려있어서!)
2. 파일명 중복을 해결할 수 없다.
클래스나 리소스 명이 같다면 하나를 포기해야 한다.
📖 편리한 부트 클래스 만들기
기존 코드를 모아서 편리하게 사용할 수 있는 클래스를 만들어서 MySpringApplication.run()을 실행하면 바로 작동하도록 했다.
✦ configClass : 스프링 설정을 파라미터로 전달받는다.
✦ args : main(args)를 전달받아서 사용한다.
public static void run(Class configClass, String[] args) {
System.out.println("MySpringApplication.main args = " + List.of(args));
//톰캣 설정
Tomcat tomcat = new Tomcat();
Connector connector = new Connector();
connector.setPort(8080);
tomcat.setConnector(connector);
//스프링 컨테이너 생성
AnnotationConfigWebApplicationContext appContext = new AnnotationConfigWebApplicationContext();
appContext.register(configClass);
//스프링 MVC 디스패쳐 서블릿 생성, 스프링 컨테이너 연결
DispatcherServlet dispatcher = new DispatcherServlet(appContext);
//서블릿 컨테이너에 디스패쳐 서블릿 등록
Context context = tomcat.addContext("", "/");
tomcat.addServlet("", "dispatcher", dispatcher);
context.addServletMappingDecoded("/", "dispatcher");
try {
tomcat.start();
} catch (LifecycleException e) {
throw new RuntimeException(e);
}
}톰캣 실행 코드는 내장 톰캣을 실행한 것처럼 똑같이 작성했다.
여기서 컴포넌트 스캔 기능이 추가딘 애노테이션을 생성하고 시작할 때 이 애노테이션을 붙여서 사용한다.
📌 애노테이션
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@ComponentScan // 스프링이 내부적으로 읽어서 인식
public @interface MySpringBootApplication {
}📌 메인 메서드
//메인 메서드
@MySpringBootApplication
public class MySpringBootMain {
public static void main(String[] args) {
System.out.println("MySpringBootMain.main");
MySpringApplication.run(MySpringBootMain.class, args);
}
}@ComponentScan을 사용했기 때문에 MySpringBootMain.class를 가지고 run()에서 register을 넣게 되면 @ComponentScan 기능이 사용된다.
@ComponentScan 위치는 @MySpringBootApplication이 붙어있는 클래스의 패키지부터 이 패키지의 하위를 모두 ComponentScan의 대상이 되기 때문에 자동으로 Bean 등록된다.
★ MySpringApplication.run(MySpringBootMain.class, args); 이 한 줄로 실행할 수 있기 때문에 편리하게 사용 가능.
결론
내장 톰캣도 실행되고 스프링 컨테이너도 생성되고 Dispatcher servlet, ComponentScan까지 종합적으로 한 방에 동작해서 부팅이 된다.
📖 프로젝트 생성, 실행 과정
implementation 'org.springframework.boot:spring-boot-starter-web'를 사용하면 내부에서 내장 톰캣을 사용한다.
@SpringBootApplication 애노테이션 : 컴포넌트 스캔을 포함한 여러 기능이 설정되어 있음. 기본 설정은 현재 패키지와 그 하위 패키지 모두를 컴포넌트 스캔.
스프링 부트 이해하겠다고 모든 코드를 알 필요는 없음.
📖 스프링 부트와 웹 서버 빌드와 배포
📌 했던대로 하면 됨.
1. cmd -> 프로젝트가 있는 곳에서 gradlew clean build
2. java -jar boot-0.0.1-SNAPSHOT.jar 실행
3. jar -xvf boot-0.0.1-SNAPSHOT.jar (풀기)
라이브러리에 boot-0.0.1-SNAPSHOT-plain.jar도 있는데 이건 딱 내가 만든 애플리케이션 코드만 있고 라이브러리는 하나도 없는 jar이다. (거의 쓸 일이 없음.)
📌 Jar 라이브러리 안에 Jar는 들어갈 수 없는데 Jar가 존재하고 인식까지 되었다. Far Jar가 아닌 처음보는 새로운 구조로 만들어져 있다.
📖 스프링 부트 - 실행 가능 Jar
Fat Jar는 단점이 존재했었다.
이 문제를 해결하기 위해 실행 가능 Jar를 만듦.
jar 내부에 jar를 포함할 수 있는 특별한 구조의 jar를 만들고 동시에 만든 jar를 내부 jar를 포함해서 실행할 수 있게 했다.
Jar 실행은 META-INF/MANIFEST.MF 파일을 찾아서 여기에 Main-Class를 읽어서 main() 메서드를 실행하게 되는데 이 때 ~.~.BootApplication이 아니라 JarLauncher라는 전혀 다른 클래스를 실행한다.
스프링 부트는 jar내부에 jar를 읽어들이는 기능이 필요하고 특별한 구조에 맞게 클래스 정보도 읽어들여야 하는데 이것들을 JarLauncher가 처리해준다.
이 작업을 처리하고나서 Start-Class: 에 지정된 main()을 호출한다.
실행 가능 Jar를 사용하지 않고 IDE에서 직접 실행할 때는 즉 public static void main(String[] args) 에서 실행하면 BootApplication.main()을 바로 실행한다.
IDE가 필요한 라이브러리를 모두 인식할 수 있게 도와주기 때문에 JarLauncher가 필요하지 않다.
☪ 정리 ➼ 빌드해서 Jar를 만들 때는 필요한데 IDE에서 라이브러리를 가져오는 방식이면 필요하지 않음.
📖 라이브러리 직접 관리
수많은 라이브러리가 있는데 내가 필요한 라이브러리가 뭔지 알고 그 라이브러리를 gradle에 넣어야 한다. 또한 버전도 맞추고 그 버전에 맞춰서 다른 라이브러리도 버전을 맞추는 (버전 호환 문제) 번거로운 작업을 해야 한다. 이것들을 모두 세팅하기에는 너무 힘들다.
그래서 스프링 부트를 사용.
📖 스프링 부트 라이브러리 버전 관리
스프링 부트는 개발자 대신에 수많은 라이브러리의 버전을 직접 관리해준다.
그래서 원하는 라이브러리만 고르고 라이브러리의 버전은 생략해도 된다. 그러면 스프링 부트가 부트 버전에 맞춘 최적화된 라이브러리 버전을 선택해준다.
id 'io.spring.dependency-management' version '1.1.0' 이것을 gradle에 설정해놓으면 버전을 모두 생략할 수 있다.
📌 dependency-management 버전 관리
이 플러그인을 사용하게 되면 spring-boot-dependencies에 있는 다음 bom 정보를 참고한다. (스프링 부트 gradle 플러그인에서 사용하기 때문에 개발자 눈에는 의존관계로 보이지는 않음.)
bom 정보는 build.gradle 문서 안에 bom이라는 항목이 있고 각각의 라이브러리에 대한 버전이 명시되어 있다.
스프링 부트가 관리하지 않는 외부 라이브러리도 있다. (대중적이지 않은 것들)
이 때는 라이브러리의 버전을 직접 적어줘야 한다.
스프링 부트가 관리하는 외부 라이브러리 버전 확인하는 방법
https://docs.spring.io/spring-boot/docs/current/reference/html/dependency-versions.html#appendix.dependency-versions.coordinates
📖 스프링 부트 스타터
이거 하나만 넣으면 스프링으로 웹 프로젝트를 시작하는데 필요한 모든 라이브러리 의존 관계를 모두 가져온다.
스프링 웹 MVC, 내장 톰캣, JSON 처리, 스프링 부트 관련, LOG, YML 등등 다양한 라이브러리가 사용된다.
implementation 'org.springframework.boot:spring-boot-starter-web'
⁂스프링과 JPA를 사용하고 싶으면 spring-boot-starter-data-jpa
★ 스프링 데이터 JPA, 하이버네이트 등등
스타터는 엄청 많음
https://docs.spring.io/spring-boot/docs/current/reference/html/using.html#using.build-systems.starters
필요한 것 갔다 쓰면 됨.
📌 라이브러리 버전 변경
만약 라이브러리의 버전을 변경하고 ext['이름'] = '10.1.4' 사용해서 바꿀 수 있다.
ex) ext['tomcat.version'] = '10.1.4'
✔ https://docs.spring.io/spring-boot/docs/current/reference/html/dependency-versions.html#appendix.dependency-versions.properties
꼭 이름을 저 사이트에 있는 이름으로 해서 버전을 바꿔줘야 한다.
📖 자동 구성 (Auto Config)
📌 데이터베이스 연동할려면 config가 필요.
@Slf4j
@Configuration
public class DbConfig {
@Bean
public DataSource dataSource() {
log.info("dataSource 빈 등록");
HikariDataSource dataSource = new HikariDataSource();
dataSource.setDriverClassName("org.h2.Driver");
// JVM 안에서 DB도 같이 메모리 모드로 띄워서 쓰기 위함.
// 단 간단한거 확인(테스트)할 때 사용한다. JVM 내리면 DB에 데이터 다 사라짐.
dataSource.setJdbcUrl("jdbc:h2:mem:test");
dataSource.setUsername("sa");
dataSource.setPassword("");
return dataSource;
}
@Bean
public TransactionManager transactionManager() {
log.info("transactionManager 빈 등록");
//dataSource() 꼭 넣기.
return new JdbcTransactionManager(dataSource());
}
@Bean
public JdbcTemplate jdbcTemplate() {
log.info("jdbcTemplate 빈 등록");
return new JdbcTemplate(dataSource());
}
}JdbcTemplate을 사용해서 회원 데이터를 DB에 보관하고 관리하는 기능이다.
DataSource, TransactionManager, JdbcTemplate을 스프링 빈으로 직접(수동) 등록.
DB는 별도의 외부 DB가 아니라서 JVM 내부에서 동작하는 메모리 DB를 사용한다.
그게 jdbc:h2:mem:test 였다.
참고 - JdbcTransactionManager == DataSourceTransactionManager 이다. (예외 처리 기능이 보강된 것 뿐!)
DB에 넣는 코드 Repository
@Repository
public class MemberRepository {
public final JdbcTemplate template;
public MemberRepository(JdbcTemplate template) {
this.template = template;
}
public void initTable() {
template.execute("create table member(" +
"member_id varchar primary key, " +
"name varchar)");
}
public void save(Member member) {
template.update("insert into member(member_id, name) values(?,?)",
member.getMemberId(),
member.getName());
}
public Member find(String memberId) {
return template.queryForObject("select member_id, name from member where member_id=?",
BeanPropertyRowMapper.newInstance(Member.class),
memberId);
// 쿼리 결과를 Member 객체로 만들어서 값을 다 넣어서 반환해준다.
// memberId는 ?에 들어갈 값.
}
public List<Member> findAll() {
return template.query("select member_id, name from member",
BeanPropertyRowMapper.newInstance(Member.class));
}
}DB에 데이터를 보관하고 관리하기 위해 JdbcTemplate, DataSource, TransactionManager를 모두 항상 스프링 빈으로 등록해야하는 번거로움이 있다. 만약 DB를 사용하는 다른 프로젝트가 있다면 이 객체들을 또 빈으로 등록해야 한다. (즉 프로젝트마다 저 객체들을 빈으로 계속 등록해야 함.)
📖 자동 구성 확인
JdbcTemplate, DataSource, TransactionManager를 빈으로 일일이 등록하지 않고 Boot에서 자동 구성으로 편리하게 등록할 수 있다.
Test시 JdbcTemplate, DataSource, TransactionManager를 모두 스프링 컨테이너에 빈으로 등록을 했는데 해당 빈들을 등록하지 않고 제거.
DbConfig에서 @Configuration을 주석처리하고 다시 Test를 실행했더니 테스트는 정상 동작하고 출력결과에 세 객체 빈들이 모두 존재.
이 빈들을 모두 스프링 부트가 자동으로 등록해 준것이다.
스프링 부트 프로젝트를 사용하면 spring-boot-autoconfigure 라이브러리가 기본적으로 사용이 되서 자동 구성이 된다. 그래서 부트가 자주 사용하는 빈들을 자동으로 등록해준다.
📖 Auto Configuration 용어
📌 자동 설정
빈들을 자동으로 등록해서 스프링이 동작하는 환경을 자동으로 설정해주기 때문에 자동 설정이라는 용어로 쓰인다.
📌 자동 구성
Configuration은 구성, 배치라는 뜻도 있어서 스프링도 스프링 실행에 필요한 빈들을 적절하게 배치해야 하기 때문에 자동 구성은 스프링 실행에 필요한 빈들을 자동으로 배치해주는 것이다. 그래서 자동 구성이라는 용어로도 쓰인다.
자동 설정은 넓게 사용되는 의미이고, 자동 구성은 실행에 필요한 컴포넌트 조각을 자동으로 배치한다는 더 좁은 의미에 가깝다고 이해!!
@Conditional : 특정 조건에 맞을 때 설정 이 동작하도록 함.
@AutoConfiguration : 자동 구성이 어떻게 동작하는지 내부 원리 이해
📖 자동 구성 예제
실시간으로 자바 메모리 사용량을 웹으로 확인해보기
//메모리 정보 조회 기능
@Slf4j
public class MemoryFinder {
public Memory get() {
long max = Runtime.getRuntime().maxMemory();
long total = Runtime.getRuntime().totalMemory();
long free = Runtime.getRuntime().freeMemory();
long used = total - free;
return new Memory(used, max);
}
//나중에 빈으로 등록할 건데 빈으로 등록됐는지 확인하기 위함.
@PostConstruct
public void init() {
log.info("init memoryFinder");
}
}JVM에서 메모리 정보를 실시간으로 조회하는 기능.
메모리 정보를 조회하는 컨트롤러
@Slf4j
@RestController
@RequiredArgsConstructor
public class MemoryController {
private final MemoryFinder memoryFinder;
@GetMapping("/memory")
public Memory system() {
Memory memory = memoryFinder.get();
log.info("memory={}", memory);
return memory;
}
}memory를 외부 라이브러리라고 가정하고 hello 패키지에서 이 라이브러리를 가져다 쓸려면 hello 패키지에 config를 등록해야 한다.
즉 hello에서 memory의 기능을 불러다 사용한다고 생각하면 됨.
hello 패키지에 MemoryConfig로 수동 빈 등록.
@Configuration
public class MemoryConfig {
@Bean
public MemoryController memoryController() {
return new MemoryController(memoryFinder());
}
@Bean
public MemoryFinder memoryFinder() {
return new MemoryFinder();
}
}
// memory 기능 가져다 쓰고 싶으면 Memory Controller, MemoryFinder 빈으로 등록그리고나서 localhost:8080/memory 를 해보면 메모리 정보가 나온다.

📖 @Conditional
메모리 조회 기능을 항상 사용하는 것이 아닌 특정 조건일 때만 해당 기능이 활성화 되도록 하기 위해 @Conditional을 사용.
같은 소스코드인데 특정 상황일 때만 특정 빈들을 등록해서 사용하도록 도와주는 기능을 한다. (스프링 부트 자동 구성에서 자주 사용함.)
이 기능 사용하기 위해선 먼저 Condition 인터페이스를 구현. (Conditional 인터페이스가 아님!!!!)
MemoryCondition
@Slf4j
public class MemoryCondition implements Condition {
@Override
public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
// 메모리 기능을 언제 활성화할 지를 지정해 줘야 함.
//-Dmemory=on (자바 시스템 속성으로 memory on)
String memory = context.getEnvironment().getProperty("memory");
log.info("memory={}", memory);
return "on".equals(memory);
//memory 값이 on이면 true 아니면 false
}
}MemoryConfig의 memoryController()와 MemoryFinder()가 어떤 상황에서는 동작해야 하고 말아야 하는지 조건을 줘야 한다.
그래서 MemoryConfig에 @Conditional(MemoryCondition.class) 애노테이션을 넣어준다.
-> 스프링이 뜰 때 먼저 @Conditional을 체크하고 MemoryCondition에서 반환 결과가 true가 나오면 config가 등록이 되고 false면 MemoryConfig를 실행하지 않는다. 그래서 빈으로 등록이 되지 않고 메모리 조회 기능이 활성화되지 않는다.
메모리 on 조건을 주고 싶다면
Run/Debug Configurations -> Modify options -> Add VM options -> -Dmemory=on 입력.
(@Conditional로 MemoryCondition를 먼저 확인해봐서 match 메서드를 실행해보니 memory가 on이어서 true 반환.)
📖 @Conditional 다양한 기능
MemoryConfig에 @ConditionalOnProperty(name = "memory", havingValue = "on") 로 property가 만족할 때 실행한다는 의미이다.
memory가 on이면 빈으로 등록한다.
(havingValue = "xx" 로 설정하면 동작하지 않는다.)
📌 다양한 @ConditionalOnXxx
@Conditional과 관련해서 조건을 부여하는 다양한 @Conditional이 있다.
1. @ConditionalClass
넣은 클래스가 있는 경우만 동작한다.
2. @ConditionalMissingClass
넣어준 클래스 이외의 클래스가 있는 경우에만 동작한다.
3. @ConditionalOnBean
빈이 등록되어 있는 경우에만 동작.
4. @ConditionalMissingBean
빈이 등록되어 있지 않는 나머지의 경우에만 동작.
5. @ConditionalProperty
환경 정보가 있는 경우 동작.
6. @ConditionalObWebApplication
웹 애플리케이션인 경우에만 동작.
7. @ConditionalOnResource
리소스가 있는 경우에만 동작.
8. @ConditionalOnExpression
SpEL 표현식에 만족하는 경우에만 동작.
주로 스프링 부트 자동 구성에 자주 사용됨.
📖 순수 라이브러리
@AutoConfiguration을 이해하기 위해선 라이브러리가 어떻게 사용되는지 이해하는 것이 중요!!!
📌 만들었던 Memory 조회 기능을 여러 프로젝트에서 사용하기.
실행 가능한 Jar가 아닌, 다른 곳에 포함되어서 사용할 순수 라이브러리 Jar를 만드는 것이 목적.
- Memory, MemoryController, MemoryFinder를 새 프로젝트에 가져옴.
- 라이브러리를 만들려면 Jar로 빌드를 해야 한다. (빌드해서 다른 곳에 뿌림.)
- cmd에서 gradlew clean build
실행했을 때 There were failing tests 에러가 발생하면 꼭 인텔리제이 설정 가서 gradle에서 IntelliJ IDEA로 수정하기!!!
이걸로도 안 되면 build.grade에서 코드를 잘못 작성한 것.
마지막 방법 Test코드 주석처리. 난 이걸로 해결함 - 압출 풀기 -> cd build/libs -> jar -xvf memory-v1.jar
memory-v1.jar는 스스로 동작하지 못하고 다른 곳에 포함되어서 동작하는 라이브러리이다.
📖 순수 라이브러리 사용
다른 프로젝트를 하나 생성했는데 이 프로젝트에는 spring-boot-starter-web과 lombok이 있다.
앞서 만든 momory-v1.jar 라이브러리를 이제 방금 새로 만든 프로젝트에 적용을 해본다.
📖 자동 구성 라이브러리 만들기
- project-v1 프로젝트에 libs 폴더를 생성하여 memory-v1.jar를 복붙.
- build.gradle에서 memory-v1.jar를 사용할 수 있도록 설정해줌.
그러면 memory-v1.jar 안에 memory, META-INF 폴더를 볼 수 있게 됨. - 만약 파일로 추가한 라이브러리를 Intellij가 인식하지 못한다면 File -> Open -> 해당 프로젝트의 build.gradle을 선택해서 Open as Project 선택.
이제 프로젝트에 라이브러리 적용하기 위해 메모리에 들어있는 Memory, MemoryController, MemoryFinder들을 빈으로 등록.
@Configuration
public class MemoryConfig {
@Bean
public MemoryFinder memoryFinder() {
return new MemoryFinder();
}
@Bean
public MemoryController memoryController() {
return new MemoryController(memoryFinder());
}
}그런데 라이브러리를 사용하는 클라이언트 개발자 입장을 생각해보면, 라이브러리 내부에 있는 어떤 빈을 등록해야 하는지 알아야 하고 하나하나 빈으로 등록해야 하고 간단한 라이브러리가 아니라 초기 설정이 복잡하다면 사용자 입장에서는 번거로운 작업이 된다.
📖 자동 구성 라이브러리 사용
만든 라이브러리를 다른 프로젝트에서도 위의 번거로운 작업없이 편하게 사용할 수 있게 해주는 것이 스프링 부트 자동 구성이다.
@AutoConfiguration
@ConditionalOnProperty(name = "memory", havingValue = "on")
public class MemoryAutoConfig {
@Bean
public MemoryController memoryController() {
return new MemoryController(memoryFinder());
}
@Bean
public MemoryFinder memoryFinder() {
return new MemoryFinder();
}
}@AutoConfiguratoin : 스프링 부트가 제공하는 자동 구성 기능을 적용할 때 사용하는 애노테이션
@ConditionalOnProperty : memory=on 이라는 환경 정보가 있을 때 라이브러리를 적용. (스프링 빈을 등록)
라이브러리를 가지고 있더라도 상황에 따라서 해당 기능을 켜고 끌 수 있게 유연한 기능을 제공.
📌 자동 구성 대상 지정 (중요)
resources에 META-INF 폴더 안에 spring 폴더 안에 파일 생성.
org.springframework.boot.autoconfigure.AutoConfiguration.imports (파일 이름)

이 파일에 memory.MemoryAutoConfig 패키지 명과 함께 써주면 자동으로 인식됨.
그러면 스프링 부트가 뜰 때 org.springframework.boot.autoconfigure.AutoConfiguration.imports 정보를 읽어서 자동 구성으로 사용한다. 따라서 내부에 있는 MemoryAutoConfig가 자동으로 실행된다.
이제 빌드한다.
cmd에서 gradle clean build
📖 자동 구성 이해 - 스프링 부트의 동작
빌드해서 memory-v2.jar가 나왔으니 이제 새 프로젝트에 적용.
- 새 프로젝트에 libs 폴더 생성
- memory-v2.jar 복사해서 libs에 붙여넣음.

- dependencies에 implementation files('libs/memory-v2.jar') 추가
그러면 libs/memory-v2.jar 안에 MemoryAutoConfig가 추가로 생김. - Modify options -> -Dmemory=on
그러면 메모리가 뜸.
📖 ImportSelector
@EnableAutoConfiguration : 자동 구성을 활성화하는 기능을 제공한다.
@Import : @EnableAutoConfiguration 안에 있는 애노테이션으로 주로 스프링 설정 정보 (@Configuration)를 포함할 때 사용한다.
@Import에 설정 정보를 추가하는 방법
1. 정적인 방법 - 설정으로 사용할 대상을 동적으로 변경할 수 없음.
@Import(클래스)
- 동적이 방법 - 코드로 프로그래밍해서 설정으로 사용할 대상을 동적으로 선택할 수 있다.
@ImportImportSelector)
스프링은 설정 정보 대상을 동적으로 선택할 수 있는 ImportSelector 인터페이스를 제공
(너무 깊이는 X.)
public class HelloImportSelector implements ImportSelector {
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
return new String[]{"hello.selector.HelloConfig"};
}
}public class ImportSelectorTest {
@Test // @Import 정적인 방식.
void staticConfig() {
AnnotationConfigApplicationContext appContext =
new AnnotationConfigApplicationContext(StaticConfig.class);
HelloBean bean = appContext.getBean(HelloBean.class);
assertThat(bean).isNotNull();
} //스프링 컨테이너를 만들 때 StaticConfig.class 설정 정보를 사용.
@Configuration
@Import(HelloConfig.class)
public static class StaticConfig {
}
//@Import 동적인 방식
@Test
void selectorConfig() {
AnnotationConfigApplicationContext appContext =
new AnnotationConfigApplicationContext(SelectorConfig.class);
// SelectorConfig 정보를 가지고 컨테이너를 만들려는데 @Import를 보니
// ImportSelector가 있으면 ImportSelector의 구현체를 호출한다.
HelloBean bean = appContext.getBean(HelloBean.class);
assertThat(bean).isNotNull();
}
// Import에 넣을 수 있는 것 중에 config이외에도 selector도 있다.
@Configuration
@Import(HelloImportSelector.class) //동적으로
public static class SelectorConfig {
}
}selectorConfig()는 SelectorConfig를 초기 설정 정보로 사용하고 SelectorConfig는 @Import(HelloImportSelector.class)에서 ImportSelector의 구현체인 HelloImportSelector를 사용했다.
스프링은 HelloImportSelector를 실행하고 hello.selector.HelloConfig라는 문자를 반환받는다.
자동 구성 동작 방식 순서
@SpringBootApplication -> @EnableAutoConfiguration -> @Import(AutoConfigurationImportSelector.class) -> resources 안에 ~~~.AutoConfiguration.imports 파일을 열어서 설정 정보 선택.
자동구성을 알야야 하는 이유
개발하다보면 사용하는 특정 빈들이 어떻게 동록된 것인지 확인이 필요할 때가 있다.
이럴 때 스프링 부트의 자동 구성 코드를 읽을 수 있어야 문제가 발생했을 때 대처가 가능하다.
📖 외부 설정
하나의 애플리케이션을 여러 다른 환경에서 사용해야 할 때가 있다.
대표적으로 개발이 잘 진행되고 있는지 확인하는 용도의 개발 환경과 실제 고객에게 서비스하는 운영 환경이 있다.
각각의 환경에 따라서 서로 다른 설정값이 존재하기 때문에 빌드는 한 번만 하고 각 환경에 맞춰서 실행 시점에 외부 설정값을 주입한다.
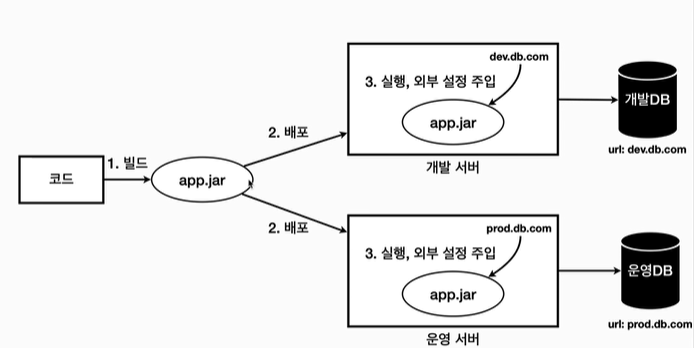
개발/운영 서버 어딘가에 값을 넣어두고 실행 시점에 값을 읽어서 사용한다.
배포 환경과 무관하게 하나의 빌드 결과물을 만든다.
설정값은 실행 시점에 각 환경에 따라 외부에서 주입한다.
개발 서버 : app.jar를 실행할 때 dev.db.com 값을 외부 설정으로 주입한다.
운영 서버 : app.jar를 실행할 때 prod.db.com 값을 외부 설정으로 주입한다.
📌 유지보수하기 좋은 애플리케이션
유지보수하기 좋은 애플리케이션의 가장 기본 원칙은 변하는 것과 변하지 않는 것을 분리하는 것이다.
각 환경에 따라 변하는 외부 설정값은 분리하고, 변하지 않는 코드와 빌드 결과물은 유지한다.
📌 필요한 설정값 외부에서 불러와서 애플리케이션에 전달.
외부 설정 4가지 방법
1. OS 환경 변수 (OS를 사용하는 모든 프로세스에서 사용.)
2. 자바 시스템 속성 (JVM 안에서 사용.)
3. 자바 커맨드 라인 인수(main(args) 메서드에서 사용.)
4. 외부 파일(외부 파일 직접 읽음.)
이 여러 방법들을 어떻게 스프링은 통합하여 편리하게 제공해 주는가 핵심이다.
📖 외부 설정 - OS 환경 변수
@Slf4j
public class OsEnv {
public static void main(String[] args) {
//시스템 환경 변수 읽어들이기.
Map<String, String> envMap = System.getenv();
for (String key : envMap.keySet()) {
log.info("env {} = {}", key, System.getenv(key));
}
}
}System.getenv() 사용하면 전체 OS 환경 변수를 Map으로 조회할 수 있다.
System.getenv(key)로 특정 OS 환경 변수의 값을 String으로 조회할 수 있다.
OS 환경 변수 설정하고 필요한 곳에서 System.getenv()를 사용하면 외부 설정을 사용할 수 있다.
DB 접근 URL과 같은 정보를 OS 환경 변수에 설정해두고 읽어들이면 된다.
ex) 개발 서버 : DBURL=dev.db.com / 운영 서버 : DBURL=prod.db.com 으로 설정하면 System.getenv("DBURL")을 조회할 때 각각 환경에 따라서 서로 다른 값을 읽게 된다.
전역 변수처럼 다른 프로그램에서도 사용할 수 있다. (한 프로그램에서만 사용하게는 할 수 없음.)
📖 외부 설정 - 자바 시스템 속성
자바 시스템 속성은 자바 프로그램을 실행할 때 사용한다.
java -Durl=dev -jar app.jar
확인하는 코드
@Slf4j
public class JavaSystemProperties {
public static void main(String[] args) {
Properties properties = System.getProperties();
for (Object key : properties.keySet()) {
log.info("prop {} = {}", key, System.getProperty(String.valueOf(key)));
}
String url = System.getProperty("url");
String username = System.getProperty("username");
String password = System.getProperty("password");
log.info("url = {}", url);
log.info("username = {}", username);
log.info("password = {}", password);
//자바를 실행할 때 -D 옵션 주기
}
}System.getProperties()로 Map과 유사한 key=value 형식의 Properties를 받을 수 있다.
모든 자바 시스템 속성을 조회 가능
System.getProperty(key)로 속성값을 조회.
자바 시스템 속성은 앞에 -D를 붙여서 key=value 형식으로 만들 수 있다.
Edit Configuration -> Modify Options -> add VM options -> -Durl=devdb -Dusername=dev_user -Dpassword=dev_pw로 설정하고 실행하면 조회가 된다.
자바 시스템 속성을 자바 코드로 설정해서 코드 안에서 사용할 수도 있지만 외부로 설정을 분리하는 효과가 사라진다.
📖 외부 설정 - 커맨드 라인 인수
@Slf4j
public class CommandLineV1 {
public static void main(String[] args) {
for (String arg : args) {
log.info("arg = {}", arg);
}
}
}Edit Configuration에서 Program arguments 입력란에 dataA dataB를 입력.
jar로 빌드되어 있다면 실행 시, 커맨드 라인 인수를 추가할 수 있다.
단 커맨드 라인은 Program arguments 입력란에 url=devdb username=dev_user password=dev_pw로 설정해도 key=value 형식으로 출력되지 않는다.
그냥 문자를 여러개 입력받는 형식으로 출력됨. (띄어쓰기로 값을 구분하여 총 값이 3개가 나옴.)
실제 애플리케이션을 개발할 때는 주로 key=value 형식을 자주 사용하는데 커맨드 라인의 경우 파싱해서 Map 같은 형식으로 변환하도록 직접 개발해야 하는 번거로움이 있다.
📖 외부 설정 - 커맨드 라인 옵션 인수
커맨드 라인 인수를 key=value 형식으로 구분하는 방법. (스프링에서 제공)
Program arguments 입력란에 --url=devdb --username=dev_user --password=dev_pw mode=on
@Slf4j
public class CommandLineV2 {
public static void main(String[] args) {
for (String arg : args) {
log.info("arg = {}", arg);
}
// key=value가 아닌 여러개의 문자열로 인식하기 때문에 변환해줌.
// 스프링이 제공해줌
// ApplicationArguments -> 인터페이스 / DefaultApplicationArguments(); -> 구현체
ApplicationArguments appArgs = new DefaultApplicationArguments(args);
log.info("SourceArgs = {}", List.of(appArgs.getSourceArgs()));
// 결과 - SourceArgs = [--url=devdb, --username=dev_user, --password=dev_pw, mode=on]
log.info("NonOptionsArgs = {}", appArgs.getNonOptionArgs());
// 결과 - [mode=on]
log.info("OptionsNames = {}", appArgs.getOptionNames());
// 결과 - [password, url, username]
// -- 없어짐
Set<String> optionNames = appArgs.getOptionNames();
for (String optionName : optionNames) {
log.info("option arg {}={}", optionName, appArgs.getOptionValues(optionName));
}
// 결과 - option arg password=[dev_pw], option arg url=[devdb], option arg username=[dev_user]
List<String> url = appArgs.getOptionValues("url");
List<String> username = appArgs.getOptionValues("username");
List<String> password = appArgs.getOptionValues("password");
List<String> mode = appArgs.getOptionValues("mode");
log.info("url = {}", url);
log.info("username = {}", username);
log.info("password = {}", password);
log.info("mode = {}", mode);
// 결과
//url = [devdb]
//username = [dev_user]
//password = [dev_pw]
//mode = null
//그러나 mode는 null. 이유는 --가 없기 때문에 그냥 문자열이어서
//key=value 형식으로 파싱하지 않아서 꺼낼 수가 없다.
}
}옵션 인수는 --로 시작한다. (mode=on처럼 --로 시작하지 않으면 옵션 인수가 아님.)
--url=devdb, --username=dev_user 이런 식으로.
--를 붙여줘야 key=value 형식으로 만들 수 있다.
위 코드에서 url, username, password, mode의 반환타입이 List인 이유는 값을 여러개 받을 수 있기 때문이다.
(--url=devdb --url=devdb2 ~~ 이런 식으로 해서 하나의 키에 여러 값을 포함할 수 있음.)
📖 외부 설정 - 옵션 인수와 스프링 부트
스프링 부트는 커맨드 라인을 포함해서 커맨드 라인 옵션 인수를 활용할 수 있는 ApplicationArguments를 스프링 빈으로 등록해둔다. 그리고 그 안에 입력한 커맨드 라인을 저장해둔다. 그래서 해당 빈을 주입받으면 커맨드 라인으로 입력한 값을 어디서든 사용할 수 있다.
@Slf4j
@Component
public class CommandLineBean {
private final ApplicationArguments arguments;
//생성자가 하나만 있기 때문에 arguments가 의존 관계 주입이 됨.
public CommandLineBean(ApplicationArguments arguments) {
this.arguments = arguments;
}
@PostConstruct
public void init() {
log.info("source = {}", List.of(arguments.getSourceArgs()));
log.info("optionNames = {}", arguments.getOptionNames());
Set<String> optionNames = arguments.getOptionNames();
for (String optionName : optionNames) {
log.info("option args {}={}", optionName, arguments.getOptionValues(optionName));
}
}
}Program arguments에 --url=devdb --username=dev_user --password=dev_pw mode=on 넣어주고 실행하면 값이 3개가 나온다.
📖 외부 설정 - 스프링 통합
외부 설정들을 모두 key=value 형식으로 사용했는데 어디에 있는 외부 설정값을 읽어야 하는지에 따라서 각각 읽는 방법이 다르기 때문에 이 문제를 Environment와 PropertySource라는 추상화를 통해서 해결해야 한다.
외부 설정값이 어디에 위치하든 일관성 있고 편리하게 key=value 형식의 외부 설정값을 읽을 수 있고 외부 설정값을 설정하는 방법도 유연해질 수 있다.
ex) OS 환경 변수를 사용하다가 자바 시스템 속성으로 변경할 경우 소스코드를 다시 빌드하지 않고 그대로 사용.
📌 PropertySource
스프링은 PropertySource라는 추상화를 제공.
각각의 외부 설정을 조회하는 xxxPropertySource라는 구현체를 만들어뒀다.
스프링은 로딩 시점에 필요한 PrpertySource들을 생성하고 Environment에서 사용할 수 있게 연결해둠.
📌 Environment
특정 외부 설정에 종속되지 않고, 일관성 있게 key=value 형식의 외부 설정에 접근할 수 있다.
environment.getProperty(key)를 통해서 값을 조회한다.
그러면 Environment는 내부에서 여러 과정을 거쳐 PropertySource(OS 환경 변수, 자바 시스템 속성, 커맨드 라인 옵션 인수, 설정데이터)를 통해 접근한다.
그래서 모든 외부 설정은 Environment를 통해 조회한다.
Environment 사용
@Slf4j
@Component
public class EnvironmentCheck {
// 스프링이 만들어준 Environment를 주입받을 수 있음.
private final Environment env;
public EnvironmentCheck(Environment env) {
this.env = env;
}
@PostConstruct
public void init() {
String url = env.getProperty("url");
String username = env.getProperty("username");
String password = env.getProperty("password");
log.info("env url={}", url);
log.info("env username={}", username);
log.info("env password={}", password);
}
}외부 설정 바꾸고 싶다면 Edit Configuration -> Modify options
따라서 외부 설정 바꿀 때는 개발 소스 코드는 전혀 변경하지 않아도 된다.
📌 PropertySource 우선순위
PropertySource마다 같은 값이 있을 수 있기 때문에 스프링은 미리 우선순위를 정해두었음.
이 우선순위는 그냥 외우지 말고 2가지만 기억.
- 더 유연한 것이 우선권 가짐.
-> 변경하기 어려운 파일보다 실행 시 원하는 값을 줄 수 있는 자바 시스템 속성이 우선권을 가짐. - 범위가 넓은 것보다 좁은 것이 우선권을 가짐.
-> 자바 시스템 속성은 해당 JVM 안에서 모두 접근할 수 있는 반면에 커맨드 라인 옵션 인수는 main의 arg를 통해서 들어오기 때문에 접근 범위가 더 좁다.
그래서 자바 시스템 속성보다 커맨드 라인 우선 옵션이 접근 범위가 더 좁아서 우선순위를 가짐.
📖 설정 데이터 - 외부 파일
OS 환경 변수, 자바 시스템 속성, 커맨드 라인 옵션 인수는 사용해야 하는 값이 늘어날 수
록 사용하기가 불편해진다. 실무에서는 수많은 설정값을 사용하기도 하므로 이런 설정값들을 프로그램을 실행할 때마다 입력하지 않고 파일에 넣어서 관리하면 된다.
그리고 애플리케이션 로딩 시점에 해당 파일을 읽어들이면 된다.
(.properties라는 파일은 key=value 형식을 사용해서 설정값을 관리하기에 아주 적합.)
☛ 해당 프로젝트 gradlew clean build
☛ build/libs/application.properties 생성.
application.properties
url=dev.db.com
username=dev_user
password=dev_pwapplication.properties에서 내가 설정한 이름대로 유연하게 수정 가능하다.
해결되지 않은 문제
1. 외부 설정을 별도의 파일로 관리하게 되면 설정 파일 자체를 관리하기 번거로운 문제가 발생.
즉 서버가 많은면 변경사항이 있을 때 이 10대 서버의 설정 파일을 모두 각각 변경해야 함 (불편)
2. 설정 파일이 별도로 관리되기 때문에 설정값의 변경 이력을 확인하기 어려움.
즉 설정값을 바꿀 때 소스코드도 같이 바뀌는 경우가 많다. 설정값의 변경 이력이 소스코드들과 어떻게 영향을 주고 받는지 그 이력을 같이 확인하기 어렵다.
📖 설정 데이터 - 내부 파일 분리
실행 시점 내부 설정 파일 조회
- 프로젝트 안에 소스 코드 뿐만 아니라 각 환경에 필요한 설정 데이터도 함께 포함해서 관리.
❆ 개발용 설정 파일 : application-dev.properties
❆ 운영용 설정 파일 : application-prod.properties - 빌드 시점에 개발, 운영 설정 파일을 모두 포함해서 빌드하고 app.jar는 개발, 운영 두 설정 파일을 모두 가지고 배포.
- 실행할 때 어떤 설정 데이터를 읽어야 할지 최소한의 구분이 필요하므로 개발환경, 운영 환경 각각
application-dev.properties, application-prod.properties 를 읽음.
실행할 때 외부 설정을 사용해서 개발 서버는 dev 운영 서버를 prod 라는 값을 제공, 운영 서버는 prod라는 값을 제공.
스프링은 이미 설정 데이터를 내부에 파일로 분리해두고 외부 설정값에 따라 각각 다른 파일을 읽는 방법을 다 구현해두었다.
개발 프로필과 운영 프로필에 각각 설정값을 넣어줌.
개발 프로필
url=dev.db.com
username=dev_user
password=dev_pw운영 프로필
url=prod.db.com
username=prod_user
password=prod_pwspring.profiles.active=dev라고 Edit Configuration -> Modify options에 쓰면 dev 프로필이 활성화된다.
application-dev.properties를 설정 데이터로 사용한다.
커맨드 라인 옵션 인수 실행은 --spring.profiles.active=dev.
자바 시스템 속성 실행은 -Dspring.profiles.active=dev
Jar 실행은
- ./gradlew clean build
build/libs 로 이동 - java -Dspring.profiles.active=dev 3. -jar external-0.0.1-SNAPSHOT.jar
- java -jar external-0.0.1-SNAPSHOT.jar --spring.profiles.active=dev
한 눈에 들어오지 않아서 보기 어렵다는 단점이 있음. 그래서 합체.
📖 설정 데이터 외부 파일 합체
dev 프로필이 활성화 될 때, prod 프로필이 활성화 될 때를 구분하여 합쳐놓는다.
spring.config.activate.on-profile=dev
url=dev.db.com
username=dev_user
password=dev_pw
#---
spring.config.activate.on-profile=prod
url=prod.db.com
username=prod_user
password=prod_pw속성 파일 구분 기호에는 선행 공백이 없어야 하며 정확히 3개의 하이픈 문자가 있어야 한다.
또한 파일을 분할하는 #--- 주석 위 아래는 주석을 적으면 안 된다.
📖 우선순위 설정 데이터
프로필을 적용하지 않고 실행하면 해당하는 프로필이 없기 때문에 키를 각각 조회하면 값은 null이 된다.
📌 기본값
내 PC에서 개발하는 것을 로컬(local) 개발 환경이라 하는데 프로필을 지정할 때 dev, prod 했던 것처럼 local이라고 지정하면서 실행하면 번거롭다.
그래서 기본값을 지정하여 프로필 지정과 무관하게 항상 사용하도록 한다.
url=local.db.com
username=local_user
password=local_pw
#---
spring.config.activate.on-profile=dev
url=dev.db.com
username=dev_user
password=dev_pw
#---
spring.config.activate.on-profile=prod
url=prod.db.com
username=prod_user
password=prod_pw프로필 정보가 없기 때문에 무조건 local부분은 읽힌다. (그래서 기본값)
📌 순서
스프링은 application.properties 설정 데이터를 읽을 때 항상 위에서 아래로 읽는다.
프로필은 2개 이상도 읽을 수 있다.
--spring.profiles.activate=dev,prod로 설정.
마지막 줄에 url=hello.db.com으로 설정해주면 다른 프로필을 활성화 하든 안 하든 항상 url은 url=hello.db.com로 적용된다.
보통은 기본값을 처음에 두고 그 뒤에 프로필이 필요한 논리 문서들을 둔다. (마지막에 두는 것은 극단적인 예시.)
📖 우선 순위 전체
더 유연하고 더 범위가 좁은게 우선순위가 높다.
높은 순으로
커맨드 라인 옵션 인수 -> 자바 시스템 속성 -> OS 환경변수
높은 순으로
jar 외부 프로필 적용 파일 -> jar 외부 -> jar 내부 프로필 적용 파일 -> jar 내부 application.properties
정리
실무에서 대부분의 개발자들은 application.properties에 외부 설정값들을 보관한다. 이렇게 설정 데이터를 기본으로 사용하다가 일부 속성을 변경할 필요가 있다면 더 높은 우선순위를 가지는 자바 시스템 속성이나 커맨드 라인 옵션 인수를 사용하면 되는 것이다.
또는 기본적으로 application.properties를 jar 내부에 내장하고 있다가 특별한 환경에서는 application.properties를 외부 파일로 새로 만들고 변경하고 싶은 일부 속성만 입력해서 변경하는 것도 가능하다.
📖 외부 설정 사용 - Environment
외부 설정값으로 application-properties에 설정.
my.datasource.url=local.db.com
my.datasource.username=username
my.datasource.password=password
my.datasource.etc.max-connection=1
my.datasource.etc.timeout=3500ms
my.datasource.etc.options=CACHE, ADMIN참고 : properties파일에는 maxConnection(낙타 표기법 -> 중간에 대문자가 들어간 것)이 아니라 max-connection으로 '-'를 사용하는 케밥 표기법을 주로 사용. 문제가 되지는 않지만 보통 properties는 케밥 표기법을 사용한다.
스프링 빈으로 등록
@Slf4j
@Configuration
public class MyDataSourceEnvConfig {
private final Environment env;
public MyDataSourceEnvConfig(Environment env) {
this.env = env;
}
@Bean
public MyDataSource myDataSource() {
String url = env.getProperty("my.datasource.url");
String username = env.getProperty("my.datasource.username");
String password = env.getProperty("my.datasource.password");
int maxConnection = env.getProperty("my.datasource.etc.max-connection", Integer.class);
Duration timeout = env.getProperty("my.datasource.etc.timeout", Duration.class);
List<String> options = env.getProperty("my.datasource.etc.options", List.class);
return new MyDataSource(url, username, password, maxConnection, timeout, options);
// 스프링 빈으로 등록.
}
}Environment.getProperty(key, Type)를 호출할 때 타입 정보를 주면 해당 타입으로 변환해준다.
📖 외부설정 사용 - @Value
외부 설정값을 편리하게 주입받을 수 있다.
@Value 사용하여 필드로 주입받기.
@Slf4j
@Configuration
public class MyDataSourceValueConfig {
@Value("${my.datasource.url}")
private String url;
@Value("${my.datasource.username}")
private String username;
@Value("${my.datasource.password}")
private String password;
@Value("${my.datasource.etc.max-connection}")
private int maxConnection; //최대 연결 수
@Value("${my.datasource.etc.timeout}")
private Duration timeout;
@Value("${my.datasource.etc.options}")
private List<String> options; //연결 시 사용하는 기타 옵션들
@Bean
public MyDataSource myDataSource() {
return new MyDataSource(url, username, password, maxConnection, timeout, options);
}
}@Value 사용하여 파라미터로 주입받기.
//@Value는 필드로 주입받을 수도 있지만 파라미터로 주입받을 수도 있다.
@Bean
public MyDataSource myDataSource2(
@Value("${my.datasource.url}")
String url,
@Value("${my.datasource.username}")
String username,
@Value("${my.datasource.password}")
String password,
@Value("${my.datasource.etc.max-connection}")
int maxConnection, //최대 연결 수
@Value("${my.datasource.etc.timeout}")
Duration timeout,
@Value("${my.datasource.etc.options}")
List<String> options) {
return new MyDataSource(url, username, password, maxConnection, timeout, options);
}만약 properties에서 키를 찾지 못한다면 기본값을 사용해서 값을 줄 수 있다.
ex) @Value("${my.datasource.etc.max-connection:2}") 이처럼 :뒤에 기본값을 적어주면 끝.
그런데 @Value로 하나하나 외부 설정 정보의 키 값을 입력받고, 주입받아와야 하는 부분이 번거로움.
그리고 설정 데이터를 보면 데이터들이 하나하나 분리되어 있는 것이 아니라 정보의 묶음으로 되어있다. (my.datasource 묶음으로 있음)
이런 부분을 객체로 변환해서 사용하게 되면 더 편리할 수 있다.
📖 외부설정 사용 - @ConfigurationProperties
타입 안전한 설정 속성 : 외부 설정값으로 올바른 타입을 입력하도록 설정해주는 것이다.
@Data
// my.datasource의 속성들을 읽어들인다는 의미.
@ConfigurationProperties("my.datasource") //이거는 빨간줄 무시.
public class MyDataSourcePropertiesV1 {
private String url;
private String username;
private String password;
private Etc etc;
// my.datasource.etc -> etc로 계층이 하나 더 붙어서 만들어줌.
@Data
public static class Etc {
private int maxConnection;
private Duration timeout;
private List<String> options = new ArrayList<>();
}
}외부 설정을 주입 받을 객체를 생성한다.
@ConfigurationProperties이 있으면 외부 설정을 주입받는 객체라는 뜻이다.
외부 설정 Key의 묶음 시작점을 적어준다. => @ConfigurationProperties("my.datasource")
@Slf4j
// MyDataSourcePropertiesV1을 사용할 수 있게 해준다.
@EnableConfigurationProperties(MyDataSourcePropertiesV1.class)
public class MyDataSourceConfigV1 {
private final MyDataSourcePropertiesV1 properties;
public MyDataSourceConfigV1(MyDataSourcePropertiesV1 properties) {
this.properties = properties;
}
@Bean
public MyDataSource dataSource() {
return new MyDataSource(
properties.getUrl(),
properties.getUsername(),
properties.getPassword(),
properties.getEtc().getMaxConnection(),
properties.getEtc().getTimeout(),
properties.getEtc().getOptions()
);
}
}@EnableConfigurationProperties : 스프링에서 사용할 @ConfigurationProperties를 지정해줘야 한다. 그러면 해당 클래스는 스프링 빈으로 등록되고, 필요한 곳에서 주입받아서 사용할 수 있다.
만약 maxConnection=abc라고 입력한다면 int가 아는 String이 들어왔기 때문에 에러가 발생한다.
📌 @ConfigurationPropertiesScan
@ConfigurationProperties를 사용하기 위해서 @EnableConfigurationProperties를 또 사용해야 했는데 그냥 ComponentScan처럼 자동으로 빈으로 등록해서 사용할 수도 있다.
main() 메서드에 넣으면 된다. (범위 지정 가능)
ex) @ConfigurationPropertiesScan({"hello"})
📖 @ConfigurationProperties 생성자
위에서 @ConfigurationProperties한 클래스의 객체들을 스프링 빈으로 등록을 했는데 Setter를 가지고 있어서 누군가가 실수로 값을 변경하는 문제가 발생할 수 있다. 이 값들은 외부 설정값을 사용해서 초기에만 설정되고, 이후에는 변경이 불가능해야 한다.
그래서 Setter를 제거하고 생성자를 사용하여 데이터를 변경하는 실수를 방지할 수 있다.
(한번 발생하면 잡기 어려운 버그가 생성됨.)
// @ConfigurationProperties 생성자를 사용하여 Setter 제거함으로써 누군가가 실수로 값을 변경하는 문제 방지.
public MyDataSourcePropertiesV2(String url, String username, String password, Etc etc) {
this.url = url;
this.username = username;
this.password = password;
this.etc = etc;
}생성자를 만들어주기만 하면 된다.
근데 에러가 발생.
Failed to bind properties under 'my.datasource.etc' to hello.datasource.MyDataSourcePropertiesV2$Etc:
Property: my.datasource.etc.max-connection
Value: "1"
Origin: class path resource [application.properties] - 4:34
Reason: java.lang.IllegalStateException: No setter found for property: max-connection
Action:
Update your application's configurationEtc에 대해서 생성자가 존재하지 않기 때문이다. 그래서 자바빈 프로퍼티방식의 Setter를 통해서 주입을 해서 에러가 발생한 것이다.
@DafaultValue : 해당 값을 찾을 수 없는 경우 기본값을 사용.
외부 설정값이 있는 application.properties에서 값을 지우고 생성자의 파라미터에 @Dafault("값")를 써주면 기본값을 사용한다.
@ConstructorBinding
생성자가 하나일 때는 생략할 수 있지만 생성자가 둘 이상이라면 선택을 해야 하기 때문에 사용할 생성자에 @ConstructorBinding 애노테이션을 적용한다.
📖 @ConfigurationProperties 검증
위에서 타입 안전 설정 @ConfigurationProperties으로 타입과 객체 문제는 해결 되었는데 숫자의 범위가 기대하는 것과 다른 경우, 예시로 max-connection의 값을 0으로 설정하면 커넥션이 하나도 만들어지지 않는 문제를 해결해야 한다.
그래서 max-connection은 최소 1이상으로 설정하지 않으면 애플리케이션 로딩 시점에 예외를 발생시켜서 빠르게 문제를 인지할 수 있도록 룰을 정한다.
@ConfigurationProperties은 자바 객체이기 때문에 스프링이 자바 빈 검증기를 사용할 수 있도록 지원한다.
spring-boot-starter-validation이 필요.
@Validated로 룰을 정해줌. (그래야 동작함)
@Getter
// my.datasource의 속성들을 읽어들인다는 의미.
@ConfigurationProperties("my.datasource") //이거는 빨간줄 무시.
@Validated
public class MyDataSourcePropertiesV3 {
@NotEmpty
private String url;
@NotEmpty
private String username;
@NotEmpty
private String password;
@NotEmpty
private Etc etc;
public MyDataSourcePropertiesV3(String url, String username, String password, Etc etc) {
this.url = url;
this.username = username;
this.password = password;
this.etc = etc;
}
// my.datasource.etc -> etc로 계층이 하나 더 붙어서 만들어줌.
@Getter
public static class Etc {
@Min(1)
@Max(999)
private int maxConnection;
@DurationMin(seconds = 1)
@DurationMax(seconds = 60)
private Duration timeout;
private List<String> options = new ArrayList<>();
public Etc(int maxConnection, Duration timeout, List<String> options) {
this.maxConnection = maxConnection;
this.timeout = timeout;
this.options = options;
}
}
}@NotEmpty : 항상 값이 있어야 한다. (필수값)
@Min(1) @Max(999) : 최소 1, 최대 999
@DurationMin(seconds = 1) : 최소 1초 허용.
@DurationMax(seconds = 60) : 최대 60초 허용.
가장 좋은 예외는 컴파일 예외, 그리고 애플리케이션 로딩 시점에 발생하는 예외.
가장 나쁜 예외는 고객 서비스 중에 발생하는 런타임 예외.
📖 YAML
- 사람이 읽기 좋은 데이터 구조를 목표로 하여 계층 구조를 이룬다.
- space(공백)로 계층 구조를 만들고 space는 1칸을 사용해도 되는데, 보통 2칸을 사용한다.
일관성있게 사용해야 읽기 쉬운 구조가 된다. - 구분 기호로 : 사용.
key: value
실무에서는 설정 정보가 많아 대부분 읽기 좋은 yml을 사용한다.
properties 파일과 yml파일을 같이 사용하면 application.properties가 우선권을 가진다.
둘이 함께 사용하는 것은 일관성이 없기 때문에 권장X.
#my.datasource.url=local.db.com
#my.datasource.username=username
#my.datasource.password=password
#my.datasource.etc.max-connection=0
#my.datasource.etc.timeout=3500ms
#my.datasource.etc.options=CACHE, ADMIN
my:
datasource:
url: local.db.com
username: local_user
password: local_pw
etc:
max-connection: 1
timeout: 60s
options: LOCAL, CACHE
---
spring:
config:
activate:
on-profile: dev
my:
datasource:
url: dev.db.com
username: dev_user
password: dev_pw
etc:
max-connection: 1
timeout: 60s
options: DEV, CACHE
---
spring:
config:
activate:
on-profile: prod
my:
datasource:
url: prod.db.com
username: prod_user
password: prod_pw
etc:
max-connection: 1
timeout: 60s
options: PROD, CACHE그냥 돌리면 local.
Activate profiles에서 dev라 쓰거나 Program arguments에서 --spring.profiles.active=dev라 쓰면 dev 프로필이 적용됨.
주의 : Activate profiles에서 dev라 써서 dev 프로필을 적용하는 것은 인텔리제이 유료 버전에서 가능. 무료 버전이면 Program arguments에서 --spring.profiles.active=dev
📖 @Profile
특정 조건이 맞으면 해당 빈을 등록하고 맞지 않으면 빈을 등록하지 않는다.
@Profile 안에는 @Conditional이 있다.
@Slf4j
@Configuration
public class PayConfig {
@Bean
@Profile("default") // 프로필 아무것도 설정하지 않으면 default -> 로컬이 등록됨.
public LocalPayClient localPayClient() {
log.info("LocalPayClient 빈 등록");
return new LocalPayClient();
}
@Bean
@Profile("prod") // prod가 등록됨. 즉 조건을 넣어줌.
public ProdPayClient prodPayClient() {
log.info("ProdPayClient 빈 등록");
return new ProdPayClient();
}
}그래서 각 환경 별로 외부 설정 값을 분리하는 것을 넘어서, 등록되는 스프링 빈도 분리할 수 있다.
ApplicationRunner : 인터페이스를 사용하면 스프링은 빈 초기화가 모두 끝나고 애플리케이션 로딩이 완료되는 시점에 run(args) 메서드를 호출해준다.
📖 액추에이터
프로덕션 준비 기능 : 운영 환경에서 서비스할 때 필요한 기능들로 프로덕션을 운영에 배포할 때 준비해야 하는 비기능적 요소들을 말한다.
개발자는 서비스에 문제가 없는지 모니터링하고 지표들을 심어서 감시하는 활둉을 해야한다.
스프링 부트가 제공하는 액추에이터가 이런 프로덕션 준비 기능을 매우 편리하게 사용할 수 있는 다양한 편의 기능들을 제공한다.
마이크로미터, 프로메테우스, 그라파나 같은 최근 유행하는 모니터링 시스템과 매우 쉽게 연동할 수 있는 기능도 제공.
📖 웹 환경에 액추에이터 기능을 노출
라이브러리는 Spring Boot Actuator, Spring Web, Spring DataJPA, H2 Database, Lombok을 선택.
액추에이터는 헬스 상태(현재 서버가 잘 동작하고 지) 뿐만 아니라 수많은 기능을 제공한다. 이 기능이 웹 환경에서 보이도록 노출할려면 yml 파일에다가 management.endpoints.web.exposure.include 입력.
management:
endpoints:
web:
exposure:
include: "*"
# 모든 것을 다 액추에이터 환경에 노출.ex) 빈이 등록됐는지 확인할 수도 있다.
📖 엔드포인트 설정
엑추에이터가 제공하는 기능 하나하나를 엔드포인트라 한다.
엔드포인트를 사용하려면 엔드포인트를 활성화한 뒤 노출시켜야 한다.
엔드포인트 활성화 : 해당 기능 자체를 사용할지 말지 on/off를 선택하는 것.
엔드포인트 노출 : 활성화된 엔드포인트를 HTTP에 노출할지 아니면 JMX(자바가 기본으로 제공하는 툴)에 노출할지 선택하는 것.
HTTP에 노출할지, JMX를 통해서 노출할지, 두 위치에 모두 노출할지 노출 위치를 지정해주어야 한다.
활성화가 되어있지 않으면 노출도 되지 않음.
엔드포인트는 대부분 기본으로 활성화되어 있고 노출이 되어 있지 않을 뿐이다.
단 shutdown은 제외. shutdown을 호출하면 서버를 내린다는 것이다.
이제 엔드포인트를 노출시키면 되는데 보통 JMX는 잘 사용하지 않으므로 HTTP에 어떤 엔드포인트를 노출할지 선택하면 된다.
management:
endpoint:
shutdown:
enabled: true
endpoints:
web:
exposure:
include: "*"
# shutdown은 기본으로 false
# 엔드포인트 활성화.
# 모든 기능을 웹에 노출시킴.만약 web에 모든 엔드포인트를 노출하지만 env, beans는 제외하고 싶다면
management:
endpoints:
web:
exposure:
include: "*"
exclude: "env,beans"
# shutdown은 기본으로 false
# 엔드포인트 활성화.
# 모든 기능을 웹에 노출시킴.
# jmx에 노출하고 싶다면 web을 jmx로 수정하면 된다.📖 다양한 엔드포인트
beans : 스프링이 컨테이너에 등록된 스프링 빈을 보여준다.
conditions : condition을 통해서 빈을 등록할 때 평가 조건과 일치하거나 일치하지 않는 이유를 표시.
configprops : @ConfigurationProperties를 보여준다.
env : Environment 정보를 보여준다.
health : 애플리케이션 헬스 정보를 보여준다.
httpexchanges : HTTP 호출 응답 정보를 보여준다. 단 HttpExchangeRepository를 구현한 빈을 별도로 등록해야 한다.
info : 애프릴케이션 정보를 보여준다.
loggers : 애플리케이션 로거 설정을 보여주고 변경도 가능하다.
metrics : 애플리케이션의 매트릭 정보를 보여준다.
mappings : @RequestMapping 정보를 보여준다.
threaddump : 쓰레드 덤프를 실행해서 보여준다.
shutdown : 애플리케이션을 종료한다. 이 기능은 기본으로 비활성화되어 있다.
📖 health 정보
애플리케이션에 문제가 발생했을 때 문제를 빠르게 인지할 수 있다.
단순히 애플리케이션이 요청에 응답을 할 수 있는지 판단하는 것 뿐만 아니라 애플리케이션이 사용하는 데이터베이스가 응답하는지, 디스크 사용량에는 문제가 없는지 같은 다양한 정보들을 포함해서 만들어진다.
health 정보를 자세히 볼려면
management:
endpoint:
shutdown:
enabled: true
health:
show-details: always
endpoints:
web:
exposure:
include: "*"만약 각각의 내부 항목들의 상태만 보고 싶다면
(반드시 endpoint 안에 health: 를 시작해야한다. endpoints가 아니다.)
management:
endpoint:
shutdown:
enabled: true
health:
show-components: always
endpoints:
web:
exposure:
include: "*"단 헬스 정보인 db, diskSpace, ping 중 하나라도 status가 DOWN이 되더 문제가 발생하면 전체 상태의 status도 DOWN이 된다.
📖 info 엔드포인트
애플리케이션의 기본 정보를 노출.
info 정보를 넣을 때는 management: 안에 바로 넣는다.
management:
info:
java:
enabled: true
os:
enabled: true
env:
enabled: true
endpoint:
shutdown:
enabled: true
health:
show-components: always
# show-details: always
endpoints:
web:
exposure:
include: "*"
# 애플리케이션에 대한 정보를 남겨 확인하고 싶을 때
info:
app:
name: hello-actuator
company: yhinfo를 활성화해두면 info 밑에 있는 외부 설정 값을 보여준다.
📌 build 정보 노출
빌드 정보 노출하려면 빌드 시점에 META-INF/build-info.properties 파일을 생성해야 한다.
build.gradle에 추가
springBoot {
buildInfo()
}추가하고 실행하면 build 폴더 -> resources -> main -> META-INF -> build-info.properties가 생성된다.
이게 빌드 정보다.
build.artifact=actuator
build.group=hello
build.name=actuator
build.time=2023-03-29T09\:20\:13.539380Z
build.version=0.0.1-SNAPSHOT📌 git 정보 노출
git 정보를 노출하려면 git.properties 파일이 필요하다.
build.gradle에 있는 plugins 안에 id 'com.gorylenko.gradle-git-properties' version '2.4.1' //git info 를 추가.
처음에는 프로젝트가 git으로 관리가 되어있지 않아서 에러가 발생한다. (plugins 안에 git이 없음.)
프로젝트를 git으로 관리
1. cmd -> cd 프로젝트 위치
- git add .
- git commit하고 start
- git log
그러면 git으로 관리가 되고 build -> resources -> main -> git.properties가 생성되는 것을 확인할 수 있다.
실행 결과로 이 빌드는 main 브랜치이고 어느 커밋에서 만들어진 것인지 확인할 수 있다.
애플리케이션을 배포할 때 원하는 동작을 하지 않을 때가 있는데 확인해보면 다른 브랜치나 다른 커밋의 내용이 배포된 경우가 종종 있다.
📖 로거
로깅과 관련된 정보를 확인하고 실시간으로 변경할 수 있다.
# 로깅 레벨 잡기 가능
logging:
level:
hello.controller: debug심각 순서 log.trace -> log.debug -> log.info -> log.warn -> log.error(가장 심각)
로깅 레벨을 잡아서 더 심각한 레벨들을 출력할 수 있다.
yml에서 hello.controller: debug로 설정했기 때문에 http://localhost:8080/actuator/loggers로 가보면 hello.controller가 "DEBUG"로 설정되어있는 것을 확인할 수 있다. (하위 패키지들도 "DEBUG")
로그를 별도로 설정하지 않으면 스프링 부트는 기본적으로 INFO를 사용한다. 그 하위도 당연히 INFO로 설정되어 있다.
📌 실시간 로그 레벨 변경
개발 서버는 보통 DEBUG 로그를 사용하지만 운영 서버는 보통 요청이 아주 많기 때문에 로그도 너무 많이 남아서 DEBUG 로그까지 모두 출력하게 되면 성능이나 디스크에 영향을 주게 된다.
그래서 운영 서버는 중요하다고 판단되는 INFO 로그 레벨을 사용한다. (일반적으로)
서비스 운영층에 문제가 있어서 급하게 DEBUG나 TRACE 로그를 남겨서 확인하고 싶다면 loggers 엔드포인트를 사용해서 애플리케이션을 다시 시작하지 않고 실시간으로 로그 레벨을 변경한다.
서버를 켰다가 다시 키면 다시 원상 복구된다.
📖 HTTP 요청 응답 기록 확인
HTTP 요청과 응답의 과거 기록을 확인하고 싶다면 httpexchanges 엔드포인트를 사용하면 된다.
HttpExchangeRepository 인터페이스의 구현체를 빈으로 등록하면 httpexchanges 엔드포인트를 사용할 수 있다. (만약 해당 빈을 등록하지 않으면 httpexchanges 엔드포인트가 활성화 되지 않는다.)
@Bean
public InMemoryHttpExchangeRepository httpExchangeRepository() {
return new InMemoryHttpExchangeRepository();
}main 메서드 있는 곳에 Bean으로 등록하면 된다.
실행해보면 지금까지 실행한 HTTP 오쳥과 응답 정보를 확인할 수 있다.
ex) request url, method, header 정보, response status, 소요 시간 등
너무 단순하고 기능에 제한이 많아 개발 단계에서만 사용하고 실제 운영 서비스에서는 모니터링 툴이나 핀포인트, Zipkin 같은 다른 기술을 사용하는 것이 좋다.
핀포인트 추천
📖 액추에이터와 보안
액추에이터가 제공하는 기능들은 애플리케이션의 내부 정보를 너무 많이 노출하여 외부 인터넷 망이 공개된 곳에 액추에이터의 엔드포인트를 공개하는 것은 보안상 좋지 않다.
그래서 외부 인터넷에서 접근이 불가능하게 막고 내부에서만 접근 가능한 내부망을 사용하는 것이 안전하다.
즉 외부 인터넷 망을 통해서 8080 포트에만 접근할 수 있게 하고 다른 포트는 내부망에서만 접근할 수 있게 하면 액추에이터에 다른 포트를 설정한다.
yml에 액추에이터 포트 설정을 하면 기존 8080 포트에서는 액추에이터를 접근할 수 없다.
management.server.port=9292
포트를 분리하는 것이 어렵고 어쩔 수 없이 인터넷 망을 통해서 접근해야 한다면 /actuator 경로에 서블릿 필터, 스프링 인터셉터 또는 스프링 시큐리티를 통해서 인증된 사용자만 접근 가능하도록 추가 개발이 필요하다.
내부망
회사 내부 사람들만 서버에 접근할 수 있도록 하고 외부 인터넷 망에서는 접근 불가능하도록 한 것.
엔드포인트 기본 경로를 변경하고 싶을 때
management:
endpoints:
web:
base-path: "/manage"/actuator 가 아닌 /manage로 변경됨.
📖 마이크로미터
많은 모니터링 툴이 있고 시스템의 다양한 정보를 이 모니터링 툴에 전달해서 사용하게 된다.
그라파나 대시보드, 핀포인트 등이 있는데 모니터링 툴이 작동하려면 시스템의 다양한 지표들을 각각의 모니터링 툴에 맞도록 만들어서 보내줘야 한다.
그런데 사용하던 툴이 아닌 다른 툴을 사용하기 위해 변경을 해버리면 기존에 측정했던 코드를 모두 변경한 툴이 맞도록 다시 변경해야 한다. 이 문제를 해결하는 것이 마이크로미터라는 라이브러리이다.
스프링 부트 액추에이터는 마이프로미터를 기본으로 내장해서 사용한다. 개발자는 마이크로미터가 정한 표준 방법으로 메트릭(츨정 지표)를 전달하면 된다. 그리고 사용하는 모니터링 틀에 맞는 구현체를 선택하면 된다. 이후에 모니터링 툴이 변경된다면 해당 구현체만 변경해서 사용하면 끝이다.
애플리케이션 코드는 모니터링 툴이 변경되어도 그래도 유지된다.
마이크로미터가 지원하는 모니터링 툴
AppOptics
Atlas
CloudWatch (유명)
Datadog (유명)
Dynatrace
Elastic (유명)
Ganglia
Graphite
Humio
Influx
Instana
JMX (유명)
KairosDB
New Relic (유명)
Prometheus (유명)
SignalFx
Stackdriver
StatsD
Wavefront
📖 메트릭(측정 지표) 확인하기
CPU, JVM, 커넥션 사용 등의 지표들은 개발자가 각각의 지표를 직접 수집해서 그것을 마이크로미터가 제공하는 표준 방법에 따라 등록하여 수집한다.
마이크로미터는 다양한 지표 수집 기능을 이미 만들어서 제공함.
그리고 스프링 부트 액추에이터는 마이크로미터가 제공하는 지표 수집을 @AutoConfiguration을 통해 자동으로 등록해준다. (스프링 부트 액추에이터로 수많은 메트릭을 편리하게 사용 가능.)
HTTP 요청수를 확인할 수도 있다.
(/log 요청해야 확인 가능)
📖 다양한 메트릭
📌 JVM 메트릭
JVM 관련 메트릭을 제공. jvm.~~로 시작함
메모리 및 버퍼 풀 세부 정보
가비지 수집 관련 통계
스레드 활용
로드 및 언로드된 클래스 수
JVM 버전 정보
JIT 컴파일 시간
📌 시스템 메트릭
시스템 메트릭을 제공. system.~~ , process., disk. 로 시작함
CPU 지표
파일 디스크립터 메트릭
가동 시간 메트릭
사용 가능한 디스크 공간
📌 애플리케이션 시작 메트릭
애플리케이션 시작 시간 메트릭을 제공.
(깊이 있게는 X.)
application.started.time : 애플리케이션을 시작하는데 걸리는 시간
application.ready.time : 애플리케이션이 요청을 처리할 준비가 되는데 걸리는 시간
ApplicationStartedEvent : 스프링 컨테이너가 완전히 실행된 상태이다. 이후에 커맨드 라인 러너가
호출된다.
ApplicationReadyEvent : 커맨드 라인 러너가 실행된 이후에 호출된다.
📌 스프링 MVC 메트릭
스프링 MVC 컨트롤러가 처리하는 모든 요청을 다룬다.
메트릭 이름 : httphtp.server.requests
TAG를 사용해서 다음 정보를 분류해서 확인할 수 있다.
uri : 요청 URI
method : GET , POST 같은 HTTP 메서드
status : 200 , 400 , 500 같은 HTTP Status 코드
exception : 예외
outcome : 상태코드를 그룹으로 모아서 확인 1xx:INFORMATIONAL , 2xx:SUCCESS ,
3xx:REDIRECTION , 4xx:CLIENT_ERROR , 5xx:SERVER_ERROR
📌 데이터소스 메트릭
DataSource, 커넥션 풀에 관한 메트릭을 확인할 수 있다.
jdbc.connections.~~ 로 시작한다.
최대 커넥션, 최소 커넥션, 활성 커넥션, 대기 커넥션 수 등을 확인할 수 있다.
히카리 커넥션 풀을 사용하면 hikaricp. 를 통해 히카리 커넥션 풀의 자세한 메트릭을 확인할 수 있다.
📌 로그 메트릭
logback.events : logback 로그에 대한 메트릭을 확인할 수 있다.
trace, debug, info, warn, error 각각의 로그 레벨에 따른 로그 수를 확인 가능.
error 로그 수가 급격히 높아지면 위험한 신호.
📌 톰캣 메트릭 (유용)
tomcat. 으로 시작.
톰캣 메트릭을 모두 사용하려면 옵션 on. (옵션 on하지 않으면 tomcat.session.~~ 관련 정보만 노출됨.)
# 톰캣 메트릭 활성화
server:
tomcat:
mbeanregistry:
enabled: true겁나 유용
tomcat.threads.config.max : tomcat thread가 고객에게 동시에 value: 200개의 요청을 받아서 처리할 수 있다는 의미.
tomcat.threads.busy : 요청이 들어온 개수. 점점 차서 200개가 되는 순간 장애 발생.
📌 기타
HTTP 클라이언트 메트릭( RestTemplate , WebClient )
캐시 메트릭
작업 실행과 스케줄 메트릭
스프링 데이터 리포지토리 메트릭
몽고DB 메트릭
레디스 메트릭
사용자가 직접 메트릭을 정의도 가능
ex) 주문수, 취소수를 메트릭으로 만들기
마이크로미터 사용법 터득이 필요.
📖 프로메테우스, 그라파나 (완전 트렌드인 툴이다.)
프로메테우스 : 애플리케이션에서 발생한 메트릭을 그 순간만 확인하는 것이 아니라 과거 이력까지 함께 확인하려면 메트릭을 보관하는 DB가 필요하다. 어디선가 메트릭을 지속해서 수집하고 DB에 저장해야 하는데 이 역할을 프로케테우스가 한다. (간단하게 메트릭을 수집하고 보관하는 DB이다.)
그라파나 : 프로메테우스가 DB였다면 이 DB에 있는 데이터를 불러서 사용자가 보기 편하게 보여주는 대시보드가 필요하다. 그라파나는 매우 유연하고 데이터를 그래프로 보여주는 툴이다.
수많은 그래프를 제공하고, 프로메테우스를 포함한 다양한 데이터 소스를 지원한다.
📖 프로메테우스 - 애프릴케이션 설정
프로케테우스가 우리 애플리케이션의 메트릭을 수집하도록 연동.
- 애플리케이션 설정 - 프로메테우스가 애플리케이션의 메트릭을 가져갈 수 있도록 애플리케이션에서 프로케테우스 포멧에 맞춰서 메트릭 만들기.
- 프로메테우스 설정 - 프로케테우스가 우리 애플리케이션의 메트릭을 주기적으로 수집하도록 설정.
각각의 메트릭들은 내부에서 마이크로키터 표준 방식으로 측정되고 있그 때무넹 어떤 구현체를 사용할지 지정만 해주면 된다.
build.gradle 추가
implementation 'io.micrometer:micrometer-registry-prometheus'추가하고 실행해보면 actuator에 prometheus가 추가된 것을 볼 수 있다.
마이크로미터 프로메테우스 구현 라이브러리를 추가한 것이고 스프링 부트와 액추에이터가 자동으로 마이크로미터 프로메테우스 구현체를 등록해서 동작하도록 설정해준다.
포맷 차이
♩ jvm.info -> jvm_info
프로메테우스는 . 대신에 _ 포맷을 사용한다.
♩ logback.events -> logback_events_total
로그수처럼 지속해서 숫자가 증가하는 메트릭을 카운터라 한다.📖 프로메테우스 - 수집 설정
다운받은 프로메테우스 폴더에 있는 prometheus.yml에다가 추가한다.
# 추가
- job_name: "spring-actuator"
metrics_path: '/actuator/prometheus'
scrape_interval: 1s
static_configs:
- targets: ['localhost:8080']join_name : 수집하는 이름. 임의의 이름 사용.
metrics_path : 수집할 경로를 지정
scrape_interval : 수집할 주기를 설정.
targets : 수집할 서버의 IP, PORT를 지정.
이렇게 설정하면 프로메테우스는 다음 경로를 1초에 한 번식 호출해서 애플리케이션의 메트릭들을 수집한다.
http://localhost:8080/actuator/prometheus
여기까지 설정 끝나면 프로메테우스 다시 실행.
http://localhost:9090/config
설정한 것 들어왔는지 확인.
- job_name: spring-actuator
honor_timestamps: true
scrape_interval: 1s
scrape_timeout: 1s
metrics_path: /actuator/prometheus
scheme: http
follow_redirects: true
enable_http2: true
static_configs:- targets:
- localhost:8080
- targets:
그리고 Status -> Targets에 들어갔더니 State가 UP으로 되어 있으면 정상이고, DOWN이면 연동이 안된 것이다.
만약 연동이 안된다면 내 액추에이터 서버 포트번호가 제대로 되어 있는지 application.yml에 가서 확인.
📖 프로메테우스 - 기본 기능
💡 프로메테우스 검색창에 http_server_requests_seconds_count 실행하면
결과
http_server_requests_seconds_count{error="none", exception="none", instance="localhost:9292", job="spring-actuator", method="GET", outcome="CLIENT_ERROR", status="404", uri="/**"}
태그, 레이블 : error, exception, instance, job, method, outcome, status, uri는 각각의 메트릭 정보를 구분해서 사용하기 위한 태그이다. 마이크로미터에서는 이것을 태그라 하고, 프로메테우스에서는 레이블이라 한다.
끝에 숫자는 해당 메트릭의 값이다.
Table은 Evaluation time을 수정해서 과거 시간 조회 가능(특정 시간의 값도 확인 가능.)하고 Graph로 메트릭을 그래프로 조회 가능하다.
💡 필터링
레이블을 기준으로 필터를 사용 가능. 중괄호{} 문법을 사용.
http_server_requests_seconds_count{uri="/log"}
log인 것만 확인.
제외도 가능
http_server_requests_seconds_count{uri!="/actuator/prometheus"}
요청 중에 GET 또는 POST를 조회하고 싶다면 http_server_requests_seconds_count{method=~"GET|POST"}
~로 정규식 사용 가능.
actuator로 시작하는 모든 것을 빼고 싶다면 http_server_requests_seconds_count{uri!~"/actuator.*"}
= ➵ 제공된 문자열과 정확히 동일한 레이블 선택.
!= ➵ 제공된 문자열과 같지 않은 레이블 선택.
=~ ➵ 제공된 문자열과 정규식 일치하는 레이블 선택.
!~ ➵ 제공된 문자열과 정규식 일치하지 않는 레이블 선택.
또한, 연산자도 가능
+, -, *, /, %, ^, sum(), count()
sum by(method, status) ➵ group by처럼 메서드와 상태를 그룹화해서 sum으로 나타냄.
topk(3, http_server_requests_seconds_count) ➵ 값이 가장 큰 상위 3개를 선택.
http_server_requests_seconds_count offset 10m ➵ 현재를 기준으로 과거 10분 전의 데이터를 나타냄.
http_server_requests_seconds_count[1m] ➵
벡터 범위 선택으로 데이터를 1분동안 모두 꺼낸다.
📖 프로메테우스 - 게이지와 카운터
메트릭은 크게 게이지와 카운터로 분류된다.
💡 게이지
임의로 오르내릴 수 있는 값.
ex) CPU 사용량, 메모리 사용량, 사용 중인 커넥션
💡 카운터
단순하게 증가하는 단일 누적 값. (단순하게 계속 증가.)
ex) HTTP 요청 수, 로그 발생 수
HTTP 요청 메트릭을 그래프로 보면 카운터여서 계속 증가하는 그래프만 보게 되는데 이렇게 증가만 하는 그래프에서는 특정 시간에 얼마나 고객의 요청이 들어왔는지 확인하기가 어렵다.
이 문제를 해결하기 위해 increase(), rate() 함수를 사용.
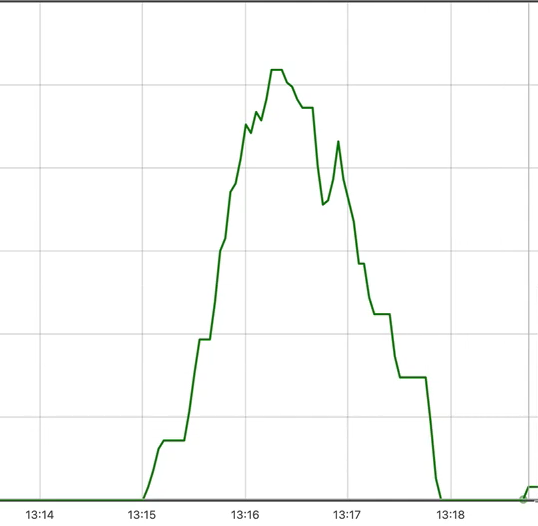
🔔 increase()
ex) increase(http_server_requests_seconds_count{uri="/log"}[1m])
요청이 없는 부분은 바닥에 깔린다.
그러면 특정 시간동안 얼마나 고객의 요청이 어느정도 증가했는지 파악할 수 있다.
🔔 rate()
ex) rate(http_server_requests_seconds_count{uri="/log"}[1m])
rate()는 초당 평균을 나누어서 계산한다. 즉 초당 얼마나 증가하는지 나타내는 지표.
🔔 irate()
범위 벡터에서 초당 순간 증가율을 계산. 급격하게 증가한 내용을 확인하기 좋음.
그런데 프로메테우스는 한눈에 들어오는 대시보드를 만들어보기 어렵다. 이 부분은 그라파나를 사용하면 된다.
📖 그라파나
그라파나는 프로메테우스를 통해서 데이터를 조회하고 보여주는 역할을 한다.
즉 데이보드의 껍데기 역할을 함.
압축을 푼 곳에서 bin 폴더로 이동하여 grafana-server.exe 실행.
그런데 애플리케이션 띄우고 프로메테우스 실행시키고 나서 그라파나 실행.
localhost:3030/
계정은 admin
🔔 프로메테우스와 연동
localhost:3000/?orgld=1 가서 설정에 Configuration -> Data sources에서 Add data source -> Prometheus 들어가서 HTTP URL에 http://localhost:9090 입력하고 Save & test
Data source is working이라는 표시가 뜨면 연동 성공.
📖 그라파나로 대시보드 만들기
Dashboards -> New에서 New Dashboard
오른쪽 상단에 Save Dashboard 해서 생성.
이제 Panel을 생성!!!!
대시보드가 큰 틀이면 패널은 그 안에 모듈처럼 들어가는 실제 그래프를 보여주는 컴포넌트이다.
Add Panel -> Builder를 Code로 수정 -> Enter a PromQL query_ 부분에 프로메테우스 쿼리를 입력. 그러면 프로메테우스에 이 쿼리를 날려서 데이터를 가져와서 그래프로 뿌려준다.
프로메테우스 쿼리 : system_cpu_usage, process_cpu_usage 등등
차트에 나온 이름 즉 범례를 바꿀 수 있음.
프로메테우스 입력한 곳 밑에 Options에서 Auto를 Custom으로 바꾸고 이름 수정 가능.
disk 용량의 경우라면 disk_total_bytes(전체 용량)
사용량을 알고 싶다면 disk_total_bytes - disk_free_bytes(남은 용량)
여러 메트릭을 추가할 수 있다.
JVM 메트릭, 시스템 메트릭, 애플리케이션 시작 메트릭, 스프링 MVC, 데이터 소스 메트릭, 톰캣 메트릭, 로그 메트릭, 기타
이렇게 많은 메트릭을 일일이 대시보드에 입력하기 힘드므르 그라파나는 이미 만들어둔 디시보드를 가져다가 사용할 수 있는 기능을 제공한다.
📖 그라파나 - 공유 대시보드 활용
여기 대시보드 많이 사용함.
🔔 Spring Boot 2.1 System Monitor (ID : 11378)
https://grafana.com/grafana/dashboards/11378-justai-system-monitor/
ID를 복사해서 그라파나 사이트에서 New -> Import -> ID 입력
Datasource는 프로메테우스로 설정.
대시보드 수정은 DashBoard settings 버튼 -> Make editable -> Save
살짝 아쉬운 점이 Tomcat에 대한 정보가 없다는 것이다.
그래서 Jetty Statistics를 Tomcat으로 바꿔서 Max는 tomcat_threads_config_max_threads로 바꿔서 Apply 해주면 최대 200개가 되고 Treads 그래프는 tomcat_threads_current_threads로 수정해서 나머지 jetty로 되어있는 2개를 삭제해주고 Apply하면 끝.
그래프에서 현재 Busy Threads가 200개가 되는 순간 Tomcat 쓰레드가 다 차서 고객 요청이 다 대기를 하게 된다. -> 대장애.
🔔 JVM 대시보드 (ID : 4701)
https://grafana.com/grafana/dashboards/4701-jvm-micrometer/
📖 그라파나 - 메트릭을 통한 문제 확인
localhost 들어가서 cpu 사용량과 jvm 메모리를 사용하는 것을 확인해봄. ??
@Slf4j
@RestController
public class TrafficController {
@GetMapping("cpu") //cpu 사용량을 그라파나에서 확인해봄
public String cpu() {
log.info("cpu");
long value = 0;
for (long i = 0; i < 10000000000L; i++) {
value++;
}
return "ok value = " + value;
}
private List<String> list = new ArrayList<>();
@GetMapping("jvm")
public String jvm() {
log.info("jvm");
for (int i=0; i<100000; i++) {
list.add("hello jvm! - " + i);
}
return "ok jvm";
}
}jdbc Connection이 고갈되는 것을 확인해봄.
요즘엔 Jdbc Template, JPA에서 커넥션을 다 닫아줘서 커넥션이 닫지 않아서 생기는 것보다는 보통 쿼리를 날렸는데 DB에서 응답이 너무 오래 걸려서 물리는 경우가 많다.
@GetMapping("/jdbc")
public String jdbc() throws SQLException {
log.info("jdbc");
Connection conn = dataSource.getConnection();
log.info("connection info={}", conn);
//스프링이 기본적으로 데이터 소스를 히카리 커넥션 풀로 세팅을 해서 히카리 커넥션 풀에서
//커넥션을 하나씩 꺼내게 되는데 커넥션을 닫지 않고 나가버리면 데드 커넥션이 된다.
//즉 계속 커넥션을 물고있는 상태로 반환이 된다.
//그러면 커넥션 액티브가 쌓여 conn은 반환이 되지 않은 상태로 남아있게 되어 큰일이 난다.
//conn.close(); //커넥션 닫지 않음.
return "ok";
}📖 모니터링 메트릭 활용
주문수, 취소수, 재고 수량 같은 메트릭들로 비즈니스의 특화된 부분들을 대시보드 구성하고 모니터링 할 수 있다.
이런 메트릭들도 시스템을 운영하는데 상당히 도움이 된다. 이럴 때 비즈니스 메트릭이 있으면 취소수 급증, 재고 수량 임계치 증가 같은 문제들을 빠르게 인지할 수 있다.
(문제 발생해도 CPU, 메모리 사용량 같은 시스템 메트릭에는 아무런 문제 발생 X.)
💀 메트릭 정의
주문수, 취소수
✔ 상품을 주문하면 주문수가 증가.
✔ 상품을 취소해도 주문수는 유지. 대신 취소수가 증가.
재고 수량
✔ 상품을 주문하면 재고 수량이 감소.
✔ 상품을 취소하면 재고 수량이 증가.
✔ 재고 물량이 들어오면 재고 수량이 증가.
주문수, 취소수는 계속 증가하므로 카운터를 사용.
재고 수량은 증가하거나 감소하므로 게이지 사용.
코드 작성->>>>>>
📖 메트릭 직접 등록 - 카운터
주문수, 최소수를 대상으로 카운터 메트릭을 등록.
MeterRegistry
마이크로미터 기능을 제공하는 핵심 컴포넌트.
Counter (카운터)
값을 나타내는 메트릭으로 증가하거나 0으로 초기화해서 다시 시작하는 기능만 지원.
단일값, 누적이므로 전체 값을 포함, 보통 하나씩 증가.
프로메테우스에서는 일반적으로 카운터의 이름 마지막에 _total을 붙여서 my_order_total과 같이 표현함.
ex) HTTP 요청수
Gauge (게이지)
카운터와 개념은 같지만 값이 증가하거나 감소할 수 있음.
따라서 하나의 값을 나타내는 경우에는 대부분 게이지를 사용해서 구현함.
@Slf4j
public class OrderServiceV1 implements OrderService {
// MeterRegistry 받기
private final MeterRegistry registry;
private AtomicInteger stock = new AtomicInteger(100);
//생성자 하나면 자동으로 빈으로 등록되면 자동으로 주입이 된다는 것 잊지 않기.
public OrderServiceV1(MeterRegistry registry) {
this.registry = registry;
}
@Override
public void order() {
log.info("주문");
stock.decrementAndGet(); //값이 줄어듬.
Counter.builder("my.order") //my.order가 메트릭 이름
.tag("class", this.getClass().getName()) //클래스 이름 넣음
.tag("method", "order") //메서드 이름 넣음.
.description("order") //설명
.register(registry).increment();
// counter.increment();
//메트릭 값이 1이 증가가 된다.
}
@Override
public void cancel() {
log.info("취소");
stock.incrementAndGet(); //값이 증가
// tag로 구분할 수 있기 때문에 name은 같아도 상관 없음.
Counter.builder("my.order")
.tag("class", this.getClass().getName())
.tag("method", "cancel") //메서드 이름으로 구분이 됨.
.description("order")
.register(registry).increment();
}
@Override
public AtomicInteger getStock() {
return stock;
}
}Counter.builder(name)을 통해서 카운터를 생성.
tag를 사용했는데 프로메테우스에서 필터할 수 있는 레이블로 사용된다.
주문과 취소는 메틕 이름은 같고 tag를 통해서 구분지음.
register(registry) : 만든 카운터를 MeterRegistry에 등록한다. (이렇게 등록해야 실제 동작한다.)
increment() : 카운터의 값을 하나 증가.
Tag, 레이블
Tag를 사용하면 데이터를 나누어서 확인할 수 있다.
Tag는 카디널리티가 낮으면서 그룹화 할 수 있는 단위에 사용해야 한다. (성별, 주문 상태, 결제 수단 등)
카디널리티가 높으면 안됨. (주문번호, PK 같은 것)
주문과 취소를 각각 호출하여 실행하면 메트릭을 볼 수 있다.
localhost:8080/actuator/metrics/my.order
프로메테우스에서는 메트릭 이름이 my.order -> my_order_total로 변경되어 있는 것을 볼 수 있다. (프로메테우스는 . -> -로 변경)
카운터는 마지막에 _total을 붙여줌.
💀 그라파나 등록 - 주문수, 취소수
Dash Board 가서 Add Panel -> 쿼리로 my_order_total{method="order"}를 넣는데 counter는 무한히 증가하기 때문에 앞에 increase()나 rate()로 묶어줌.
increase(my_order_total{method="order"}[1m])
📖 메트릭 편리한 등록 - @Counted
직접 메트릭을 등록한 방법으로 Counter.builder()를 사용해서 tag를 쓰고 한 것들은 가장 큰 단점으로 메트릭을 관리하는 로직이 핵심 비즈니스 개발 로직에 침투했다는 것이다.
이런 부분을 분리하고 싶다면 스프링 AOP를 사용하면 된다.
메서드에다가 @Counted("my.order") 써주면 끝!!!
@Counted 애노테이션을 측정을 원하는 메서드에 적용한다. 그리고 메트릭 이름을 지정하면 된다.
이렇게 사용하면 자동으로 tag에 method 이름을 기준으로 분류해서 적용한다.
@Configuration
public class OrderConfigV2 {
@Bean
public OrderService orderService() {
return new OrderServiceV2();
}
@Bean
public CountedAspect countedAspect(MeterRegistry registry) {
return new CountedAspect(registry);
//CountedAspect가 있어야 @Counted를 인식해서 AOP가 동작하게 해준다.
}
}중요 🚨 CountedAspect를 빈으로 등록하지 않으면 @Counted 관련 AOP가 동작하지 않는다.
📖 메트릭 등록 - Timer
특별한 메트릭 측정 도구로 시간을 측정하는데 사용된다.
카운터와 유사하고 실행 시간도 함께 측정할 수 있다.
@Slf4j
public class OrderServiceV3 implements OrderService {
private final MeterRegistry registry;
private AtomicInteger stock = new AtomicInteger(100);
public OrderServiceV3(MeterRegistry registry) {
this.registry = registry;
}
@Override
public void order() {
Timer timer = Timer.builder("my.order")
.tag("class", this.getClass().getName())
.tag("method", "order")
.description("order")
.register(registry);
timer.record(() -> {
// 내부에서 측정해서 호출 시작부터 끝날 때까지의 시간을 측정
log.info("주문");
stock.decrementAndGet(); //값이 줄어듬.
sleep(500);
});
}
@Override
public void cancel() {
Timer timer = Timer.builder("my.order")
.tag("class", this.getClass().getName())
.tag("method", "cancel")
.description("order")
.register(registry);
timer.record(() ->{
log.info("취소");
stock.incrementAndGet(); //값이 증가
sleep(200);
});
}
@Override
public AtomicInteger getStock() {
return stock;
}
private static void sleep(int l) {
try {
// 최대 시간 확인을 위함. 기본 500에서 +- 200ms
Thread.sleep(l + new Random().nextInt(200));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
order, cancel 호출하면 할수록 TOTAL_TIME이 증가한다.
TOTAL_TIME : 실행 시간의 합 (각각의 실행 시간의 누적 합.)
MAX : 최대 실행 시간 (가장 오래 걸린 실행 시간.)
Timer.builder(name)을 통해서 타이머를 생성.
register(registry) : 만든 타이머를 MeterRegistry에 등록해야 실제 동작한다.
타이머를 사용할 때는 timer.record()를 사용하면 된다. () 안에 시간을 측정할 내용을 함수로 포함하면 된다.
프로메테우스로 다음 접두사가 붙으면서 3가지 메트릭을 제공한다.
seconds_count : 누적 실행 수
seconds_sum : 실행 시간의 합
seconds_max : 최대 실행 시간(가장 오래 걸린 실행 시간)
여기서 평균 실행시간도 계산 가능
seconds_sum / seconds_count = 평균 실행시간
걸리는 시간을 확인하기 위해 0.5초, 0.2초 대기하도록 했는데 추가로 가장 오래 걸린 시간을 확인하기 위해 sleep()에서 최대 0.2초를 랜덤하게 더 추가했다 (모두 0.5초로 같으면 가장 오래 걸린 시간을 확인하기 어렵다.)
💀 그라파나 등록 - 실행시간
주문/취소 실행시간 : increase(my_order_seconds_count{method="order"}[1m]) / increase(my_order_seconds_count{method="cancel"}[1m])
최대 실행시간 : my_order_seconds_max
평균 실행시간 : increase(my_order_seconds_sum[1m]) / increase(my_order_seconds_count[1m])
📖 메트릭 등록 @Timed
@Timed("my.order") 이런 식으로 타입(클래스에다가)이나 메서드 중에 적용할 수 있다.
그러면 해당 타입의 모든 public 메서드에 타이머가 적용된다.
🚨 중요(꼭 넣어줘야 함) : @Timed를 쓸 경우 AOP에 등록이 되도록 따로 TimedAspect를 빈으로 등록해야 한다.
@Configuration
public class OrderConfigV4 {
@Bean
OrderService orderService() {
return new OrderServiceV4();
}
//반드시 넣어줘야 동작함.
@Bean
public TimedAspect timedAspect(MeterRegistry registry) {
return new TimedAspect(registry);
}
}직접 등록하는 방법보다 당연히 자동으로 애노테이션 사용해서 등록하는 것이 편하다.
그렇지만 내부 원리를 이해하기 위해 직접 등록하는 것도 공부해본 것이다.
그리고 항상 AOP를 사용할 수 있는 것도 아니므로 한 번 알아두는 것이 좋다.
📖 게이지
임의로 오르내릴 수 있는 단일 숫자 값을 나타내는 메트릭. (값이 증가/감소 가능)
값의 현재 상태를 보는데 사용된다.
ex) 차량의 속도, CPU 사용량, 메모리 사용량
카운터와 게이지의 차이는 값이 감소할 수 있는지를 보면 된다.
@Configuration
public class StockConfigV1 {
@Bean
public MyStockMetric myStockMetric(OrderService orderService, MeterRegistry meterRegistry) {
return new MyStockMetric(orderService, meterRegistry);
}
//내부에 측정하는 클래스를 만듦.
@Slf4j
static class MyStockMetric {
private OrderService orderService;
private MeterRegistry registry;
public MyStockMetric(OrderService orderService, MeterRegistry registry) {
this.orderService = orderService;
this.registry = registry;
}
@PostConstruct
public void init() {
Gauge.builder("my.stock", orderService, service -> {
log.info("stock gauge call");
//우리가 측정해야 하는 값은 현재 재고 수량 값이다.
//이 리턴값이 외부에서 호출될 때 측정값으로 사용되는 것이다.
return service.getStock().get();
}).register(registry);
}
}
}게이지를 만들 때 함수를 전달했는데 이 함수는 외부에서 메트릭을 확인할 때마다 호출된다.
이 함수의 반환값이 게이지의 값이다.
실행해보면 1초에 한 번씩 log 찍은 "stock gauge call"이 호출된다. 프로메테우스가 경로를 1초에 한 번씩 호출하도록 설정되어 있어서 그런 것이다.
(프로메테우스를 끄면 남지 않음.)
🚨 만약 게이지를 측정했는데 측정값이 나오지 않는다면 MeterRegistry registry가 등록이 되지 않은 것일 수 있다.
.register(registry); 를 꼭 넣어서 등록해주자.
📖 게이지 단순하게 등록
MeterBinder를 사용해서 반환해준다.
@Slf4j
@Configuration
public class StockConfigV2 {
@Bean
public MeterBinder stockSize(OrderService orderService) {
return registry -> Gauge.builder("my.stock",
orderService, service -> {
log.info("stock gauge call!!");
return service.getStock().get();
}).register(registry);
// register()의 반환 타입이 MeterBinder이기 때문에 반환해주면 알아서 등록해준다.
}
}🔑 Micrometer
메트릭은 100% 정확한 숫자를 보는데 사용하는 것이 아니다. 약간의 오차를 감안하고 실시간으로 대략의 데이터를 보는 목적으로 사용해야 한다.
📖 실무 모니터링 환경 팁
애플리케이션 모니터링 할 때는 3가지 단계를 기억.
🦉. 대시보드
🦉. 애플리케이션 추적 - 핀포인트
🦉. 로그
🩸 대시보드 - 전체를 한 눈에 볼 수 있는 가장 높은 뷰
모니터링 대상으로 시스템 메트릭(CPU, 메모리), 애플리케이션 메트릭(톰캣 쓰레드 풀, DB 커넥션 풀, 애플리케이션 호출 수), 비즈니스 메트릭(주문수, 취소수)
대시보드로는 마이크로미터, 프로메테우스, 그라파나 등을 사용.
🩸 애플리케이션 추적 - 핀포인트
주로 각각의 HTTP 요청을 추적, 일부는 마이크로서비스 환경에서 분산 추적
🔜 대시보드는 전체를 보는 것이지만 애플리케이션 추적은 고객의 HTTP 요청 하나하나에 대해서 추적을 하는 것이다. 그리고 마이크로서비스 상황에서는 A서버 -> B서버 -> C서버로 건너가면서 호출이 될 수 있어 고객의 요청이 어떻게 흘러가는지 볼 수 있는 것을 분산 추적이라 한다.
핀포인트(매우 잘 만듦, 추천), 스카우트, 와텝, 제니퍼(유명) 등
핀포인트는 대용량 트래픽에도 잘 버티고 설계가 잘 되어 있음.
🩸 로그
가장 자세한 추적, 원하는데로 커스텀 가능.
로그가 필요한 건 대시보드, 애플리케이션 추적으로 드러나지 않는 문제를 발견하기 위함.
ex) 비즈니스 로직
주의) 로그를 남길 때는 이 로그가 하나의 고객의 요청에서 나온 로그라는 것을 묶어서 볼 수 있도록 해야 한다. 그렇지 않으면 어떤 사용자가 호출했는지 모르고 한 사용자가 호출하더라도 언제 HTTP를 요청한 것인지 로그가 섞여서 나올 수도 있다.
그래서 HTTP 요청이 들어가서 로그를 남기고 나갈 때 "하나의 HTTP 요청에서 나온 로그다." 라는 것을 묶어서 보는 것이 제일 좋다. 그럴려면 고객 요청이 들어올 때 유효한 랜덤 아이디를 하나 만들어서 고객 요청이 들어와서 나갈 때까지 생성된 랜덤 아이디를 같이 로그를 남긴다. 그러면 같은 사용자의 로그라는 것을 알 수 있다.
로그가 매우 많아 수동으로 다 할 수 없으므로 자동으로 하기 위해 MDC를 적용한다.
같은 HTTP 요청에 대해서 같은 ID로 남는다.
로그가 멀티쓰레드 상황이어서 아이디 대로 묶여서 나오지 않고 섞여서 나오므로 묶어서 나오도록 만들어야 한다.
적용 예시)
[7uller] "안녕!!"
[7uller] "~"~"
[7uller] "ㅋㅋㅋㅋㅋㅋㅋ"
[8ilier] "안녕!!"
[8ilier] "
[8ilier] "ㅋㅋㅋㅋㅋㅋㅋ"
파일로 직접 로그를 남기는 경우에는 일반 로그와 에러 로그는 파일을 구분해서 남겨야 한다. 구분하지 않으면 에러 로그가 일반 로그에 묻혀서 보이지 않는다.
그래서 에러 로그는 별도의 파일로 남겨야 한다.
에러 로그만 확인해서 문제를 바로 정리 가능.
클라우드에 로그를 저장하는 경우는 검색이 잘 되도록 구분한다.
📖 실무 모니터링 - 알람
모니터링 툴에서 일정 이상 수치가 넘어가면 슬랙(주로 사용), 문자 등을 연동해서 알람을 받는 것이 좋다. (슬랙에다가 채널을 하나 만들어서 알람이 오게 한다.)
🔖 알람은 경고와 심각 2가지 종류로 꼭 구분해서 관리해야 한다.
경고는 하루 1번 정도 사람이 직접 확인해도 되는 수준 (사람이 들어가서 확인)
심각은 즉시 확인해야 함. 슬랙 알림(앱을 통해 알림을 받도록), 문자, 전화
예시)
디스크 사용량 70% -> 경고
CPU 사용량 60% -> 심각
슬랙에서는 경고방과 심각 알람방을 꼭 구분!!!!
경고와 심각을 잘 나누어서 업무와 삶에 방해가 되지 않도록 해야 함.
거짓(False) 알람으로 애매한 알람들 즉 확인하지 않아도 되는 알람들은 과감히 정리.

0개의 댓글



안정적인 운영을 완성하는 모니터링, 프로메테우스와 그라파나
메트릭이란?시계열 데이터베이스란?애너테이션으로 매트릭 수집하기멀티 컨테이너 패턴다양한 종류의 프로메테우스 익스포터PromQL 정규 표현식쿠버네티스 내에서 도메인 이름을 제공하는 CoreDNSSLI, SLO, SLA경보 메세지의 출력은 왜 느린가요?본 게시물은 "컨테이너...


🎤 prometheus(프로메테우스) 설치 및 실행
초보개발자가 배우는 단계에서의 포스트 글입니다. 부족한 점이 많이 있을 수 있습니다. 이해해주세요..😂😂 🚀 시작에 앞서서... >이번 시간에는 프로메테우스를 설치하고 실행해보는 시간을 갖도록 하겠습니다. 저는 AWS t2.micro를 사용해서 리눅스 환경에서...

서블릿 컨테이너와 스프링 컨테이너
출처: https://12bme.tistory.com/555위 출처의 내용을 그대로 받아 적은 게시물이며, 내용을 더 잘 이해하기 위한 활동입니다.서블릿 컨테이너는 개발자가 웹서버와 통신하기 위하여 소켓을 생성하고, 특정 포트에 리스팅하고, 스트림을 생성하는 ...


[Spring Boot] 스프링과 스프링 부트
Spring과 SpringBoot의 각 개념과 특징을 공부하고 정리한 포스팅입니다. 스프링의 특징인 제어의 역행, 의존성 주입, AOP에 대해 다뤘으며 스프링과 스프링 부트의 비교를 정리했습니다.


[Spring Core] 스프링이란?
스프링은 어떤 특정한 하나가 아니라 여러가지 기술들의 모음이라고 할 수 있다.핵심기술 : 스프링 DI 컨테이너, AOP, 이벤트, 기타웹기술 : 스프링 MVC, 스프링 WebFlux데이터 접근 기술 : 트랜잭션, JDBC, ORM 지원, XML 지원기술 통합 : 캐시,...





[SpringBoot]스프링부트란?
한이음 회의를 진행하며 어떤 아이디어라도 무조건 필요한 약국 상세정보 데이터와 약품 상세정보 데이터는 필요했다. 우리는 두 데이터를 아이디어 회의를 진행하며 먼저 DB에 적재하기로 하였다. 멘토님께서는 Spring Boot를 활용해보는 것을 추천하셨다. 나 포함 팀원 ...




'공부방 > Spring' 카테고리의 다른 글
| 스프링부트 (0) | 2023.04.23 |
|---|---|
| 스프링 프레임워크의 등장 배경 (0) | 2023.04.23 |
| [Mysql] order by, group by (0) | 2023.01.10 |
| deleteById, deleteByName (0) | 2022.09.30 |
| [오류] FK가 PK가 아닌 다른 컬럼과 연관관계가 있을 때 (0) | 2022.08.31 |


